
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- expo
- React
- kaggle
- 사이드프로젝트
- FirebaseV9
- 데이터분석
- coding
- Ros
- JavaScript
- App
- clone coding
- 클론코딩
- GYM
- 딥러닝
- Instagrame clone
- selenium
- 강화학습
- TeachagleMachine
- Reinforcement Learning
- ReactNative
- 강화학습 기초
- 머신러닝
- 전국국밥
- python
- redux
- 조코딩
- 앱개발
- 리액트네이티브
- 카트폴
- pandas
- Today
- Total
qcoding
[데이터분석실습]mpg 데이터를 통한 분석 (query 사용법 / query 변수 / query in) 본문
# #mpg 데이터를 분석하여 데이터 분석실습하기
https://github.com/youngwoos/Doit_Python/tree/main/Data
GitHub - youngwoos/Doit_Python: <Do it! 쉽게 배우는 파이썬 데이터 분석> 저장소
<Do it! 쉽게 배우는 파이썬 데이터 분석> 저장소. Contribute to youngwoos/Doit_Python development by creating an account on GitHub.
github.com
1) 데이터 가져오기
import pandas as pd
import numpy as np
#pandas 출력 제한설정하기
pd.set_option('display.max_rows',30)
pd.set_option('display.max_columns',30)
df=pd.read_csv('./mpg.csv')
df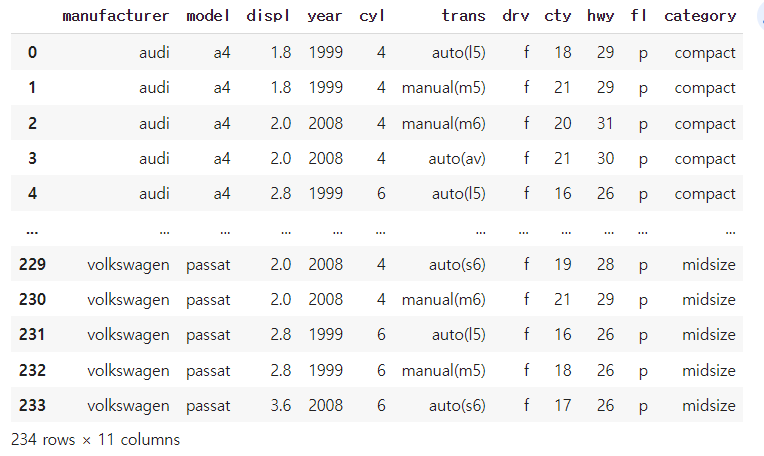
2) displ(배기량)이 4이하인 자동차와 5이상인 자동차 중 어떤 자동차의 hwy(고속도로 연비) 평균이 더 높은 지 알아보세요.
# hwy 연비 평균비교
displ_4_under=df.query('displ<=4')
displ_4_under_hwy=displ_4_under['hwy'].mean()
displ_5_over=df.query('displ>=5')
displ_5_over_hwy=displ_5_over['hwy'].mean()
print(f'displ 4이하 연비 : {round(displ_4_under_hwy,2)} , displ 5이상 연비 : {round(displ_5_over_hwy,2)}')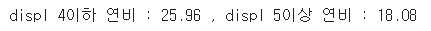
2) 자동차 제조 회사에 따라 도시 연비가 어떻게 다른지 알아보려고 합니다. 'audi' 와 'toyota' 중 어느 manufacturer의 cty 평균이 더 높은지 알아보세요.
# 제조사 별 이름 확인
df['manufacturer'].unique()
# 변수로 이름을 사용할 때에는 @변수 를 사용해서 query를 작성하면 된다.
# 제조사별 연비확인
au= 'audi'
to= 'toyota'
# audi / toyota query 활용하여 행추출
audi=df.query('manufacturer == @au')
toyota=df.query('manufacturer == @to')
#cty 연비확인
audi_city=audi['cty'].mean()
toyota_city=toyota['cty'].mean()
print(f'audi_ctiy : {audi_city} , toyota_city : {toyota_city} ')3) 'chevrolet', 'ford', 'honda' 자동차의 고속도로 연비 평균을 알아보려고 합니다. 세 회사의 데이터를 추출한 다음 hwy 전체 평균을 구해보세요.
# 여러개의 조건을 만족하는 or 조건 계산시 in을 사용하여 코드를 간결하게 할수 있음
avg_hwy=df.query('manufacturer in ["chevrolet","ford", "honda"]')
avg_hwy['manufacturer'].unique()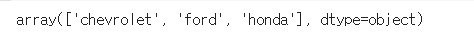
avg_hwy_=avg_hwy['hwy'].mean()
print(f"hwy 연비 : {avg_hwy_}")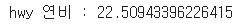
4) mpg 데이터에서 category(자동차 종류), city(도시연비) 변수를 추출해 새로운 데이터를 만들세요. 새로만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는 지 확인해 보세요.
## 필요한 변수 추출하기
df_new=df[['category','cty']]
df_new.head()
5) 자동차 종류에 따라 도시 연비가 어떻게 다른 지 알아보려고 합니다. 앞에서 추출한 데이터를 이용한 category(자동차 종류)가 'suv' 자동차와 'compact'인 자동차 중 어떤 자동차의 cty(도시연비) 평균이 더 높은지 알아보세요.
suv_cty=df_new.query('category == "suv"')['cty'].mean()
compact_cty=df_new.query('category == "compact"')['cty'].mean()
print(f'suv 연비 : {round(suv_cty,2)}, compact 연비 : {round(compact_cty,2)}')
6) 'audi'에서 생상한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은 지 알아보려고 합니다. 'audi'에서 생상한 자동차 중 hwy가 1~5위에 해당하는 자동차 데이터를 출력하세요.
audi=df.query('manufacturer=="audi"').sort_values('hwy',ascending=False)
audi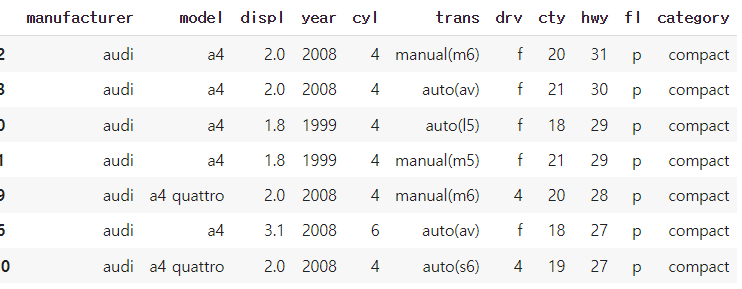
7) mpg 데이터 복사본을 만들고, cty와 hwy를 더한 '합산 연비 변수'를 추가하세요
#합산 연비 변수 추가
#복사
df_copy=df.copy()
#합산 연비 변수추가
df_copy=df_copy.assign(sum_fe= lambda x:x['cty']+x['hwy'])
df_copy
8) 앞에서 만든 합산 연비변수를 2로나눠 평균연비 변수를 추가하세요.
#합산 연비 변수추가
df_copy=df_copy.assign(avg_fe= lambda x:x['sum_fe']/2)
df_copy
9) 평균 연비변수가 가장 높은 자동차 3종의 데이터를 출력하세요.
# 평균 연비 변수가 높은 3종의 자동차
df_copy.sort_values('avg_fe',ascending=False).head(3)
10) 7~9번 문제를 해결할 수 있는 하나로 연결된 pandas 구문을 원본데이터를 활용하여 만들어 보세요.
# 하나로 연결된 pandas 구문
df.assign(
sum_fe=lambda x:x['cty']+x['hwy'],
avg_fe=lambda x:x['sum_fe']/2
).sort_values('avg_fe',ascending=False).head(3)
11) 제조 회사별로 'suv' 자동차의 도시 및 고속도로 합산 연비 평균을 구해 내림차순으로 정렬하고 1~5위까지 출력하기
--> 각각를 단위로 나눠서 생각해보기
| 절차 | 기능 | pandas 함수 |
| 1 | suv 추출 | query() |
| 2 | 합산 연비 변수 만들기 | assign() |
| 3 | 회사별로 분리 | groupby() |
| 4 | 합산 연비 평균 구하기 | agg() |
| 5 | 내림차순 정렬 | sort_values() |
| 6 | 1~5위까지 출력 | head() |
df.query('category=="suv"')\ // suv 추출
.assign(
sum_fe=lambda x:x['cty']+x['hwy'], // 합산 연비 만들고
avg_fe=lambda x:x['sum_fe']/2 // 평균 연비 만들고
).groupby('manufacturer')\ // 제조사별로 그륩을 만들고
.agg(avg_fe_mean=('avg_fe','mean'))\ // 평균연비들의 평균을 구함
.sort_values('avg_fe_mean',ascending=False)\ // 평균연비들의 평균으로 내림차순으로 정렬함
.head(5) // 상위 5개를 출력함
11) mpg 데이터의 category는 자동차를 특징에 따라 일곱 종류로 분류한 변수입니다. 어떤 차종의 도시 연비가 높은지 비교해 보려고 합니다. category별 cty 평균을 구하고, 평균 연비가 높은 것부터 내림차순으로 정렬해보세요
df.groupby('category').agg(
cty_avg=('cty','mean')
).sort_values('cty_avg',ascending=False)
12) 어떤 회사 자동차의 hwy 연비가 가장 높은지 알아보려고 합니다. hwy 평균이 가장 높은 회사 세곳을 출력하세요.
df.groupby('manufacturer').agg(
avg_hwy=('hwy','mean')
).sort_values('avg_hwy',ascending=False).head(3)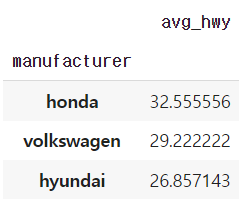
13) 어떤 회사에서 compact 차종을 가장 많이 생산하는 지 알아보려고 합니다. 회사별 compact 차종 수를 내림차순으로 정렬해 출력하세요.
| 절차 | 기능 | pandas 함수 |
| 1 | compact 차종추출 | query() |
| 2 | 회사별 구분 | groupby() |
| 3 | 차종의 수 | agg() 에서 count 사용 |
| 4 | 내림차순정렬 | sort_values() |
df.query('category=="compact"')\
.groupby('manufacturer')\
.agg(
count_compact=('manufacturer','count')
).sort_values('count_compact',ascending=False)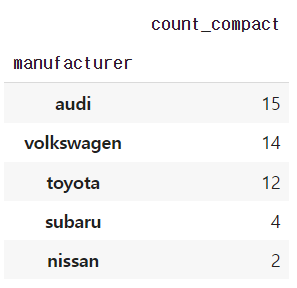
13) mpg 데이터의 f1변수는 자동차에 사용하는 연료를 의미합니다. 다음은 자동차 연료별 가격을 나타낸 표입니다.
| f1 | 연료 종류 | 가격(갤런당 USD) |
| c | CNG | 2.35 |
| d | diesel | 2.38 |
| e | ethanol E85 | 2.11 |
| p | premium | 2.76 |
| r | regular | 2.22 |
우선 이 정보를 이용해 연료와 가격으로 구성된 데이터 프레임을 만들어 보세요.
fuel=pd.DataFrame({
"f1":["c","d","e","p","r"],
'price_f1':[2.35,2.38,2.11,2.76,2.22]
})
fuel
mpg 데이터에서 연료 종류를 나타낸 f1 변수는 있지만 연료가격을 나타낸 변수는 없습니다.
앞에서 만든 fuel 데이터를 이용해 mpg 데이터에 price_f1 변수를 추가하세요.
## 데이터 합치기
# 가로 (열)로 합치기
df=pd.merge(df,fuel,how='left',on='fl')
df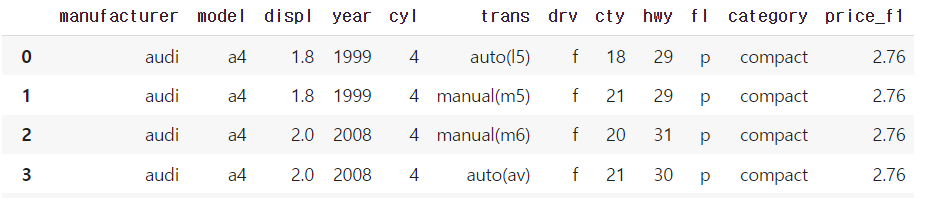
14) 연료 가격 변수가 잘 추가 됐는지 확인하기 위해 model,fl,price_fl 변수를 추출해 앞부분 5행을 출력해보세요.
df[['model','fl','price_f1']].head(5)
15) mpg 데이터 원본에는 결측치가 없습니다. 다섯행의 hwy 변수에 NaN을 할당합니다.
drv별로 hwy 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기전에 우선 두 변수에 결측치가 있는지 확인해야 합니다. drv변수와 hwy 변수에 결측치가 몇개 있는지 알아보세요.
## 결측치 입력
df.loc[[64,123,130,152,211],'hwy']=np.nan
df
# 결측치 확인
df[['drv','hwy']].isna().sum()
16) df.dropna()를 이용해 hwy 변수의 결측치를 제거하고, 어떤 구동 방식의 hwy 평균이 높은지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다.
# drop나 이용 결측치제거
df.dropna(subset=['hwy']).groupby('drv').agg(mean_hwy=('hwy','mean')).sort_values('mean_hwy',ascending=False)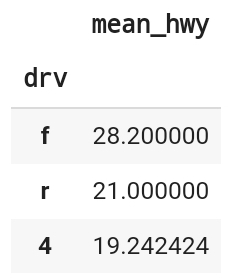
17) mpg 데이터를 불러와 일부러 이상치를 만들겠습니다. drv 변수의 값은 4,f,r 세종류입니다. 몇개의 행에 존재할 수 없는 값 k를 할당하겠습니다. cty 변수도 몇개의 행에 극단적으로 크거나 작은 값을 할당하겠습니다.
# 이상치 생성
df.loc[[9,13,57,92],'drv']='k'
df.loc[[28,42,128,202],'cty']=[3,4,39,42]drv에 이상치가 있는지 확인하세요. 이상치를 결측 처리한 다음 이상치가 사라졌는지 확인하세요. 결측 처리를 할 때는 df.isin()을 활용하세요.
# drv 이상치 확인
df['drv'].value_counts().sort_index()
#이상치 처리
df['drv']=np.where(df['drv'].isin(['f','4','r']),df['drv'],np.nan)
#이상치 -> 결측치로 이상치 제거 확인
df['drv'].value_counts().sort_index()
18) 상자 그림을 이용해 cty에 이상치가 있는 지 확인하세요. 상자 그림 기준으로 정상 범위를 벗어난 값을 결측 처리한 다음 다시 상자 그림을 만들어 이상치가 사라졌는지 확인하세요.
# 이상치 제거를 위해 qutile() 사용하기 IQR 을 통해 상/하한을 구함
# 1사분위 (0.25)
pct_25=df['cty'].quantile(0.25)
# 3사분위 (0.75)
pct_75=df['cty'].quantile(0.75)
print(f'1사분위 : {pct_25} , 3사분위 :{pct_75}')
#IQR 계산
iqr=pct_75-pct_25
print(f'iqr : {iqr}')
#상/하한 설정
upper=pct_75 + 1.5 * iqr
lower=pct_25 - 1.5 * iqr
print(f'상한 : {upper}, 하한 :{lower}')
#이상치 제거
df['cty']=np.where(
(df['cty'] > 26.5 ) | (df['cty'] < 6.5),
np.nan,
df['cty']
)
#이상치제거확인
sns.boxplot(data=df,y='cty')
19) 두 변수의 이상치를 결측 처리했으니 이제 분석할 차례입니다. 이상치를 제거한 다음 drv 별로 cty 평균이 어떻게 다른지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다.
# 결측치 제거 후 drv별로 cty 평균확인
df.dropna(subset=['drv', 'cty']).groupby('drv').agg(
mean_cty=('cty','mean')
).sort_values('mean_cty',ascending=False)
20) mpg데이터의 cty와 hwy 간에 어떤 관계가 있는 지 알아보려고 합니다. x축은 cty, y축은 hwy로 된 산점도를 만들어 보세요.
sns.scatterplot(data=df,x='cty' , y='hwy')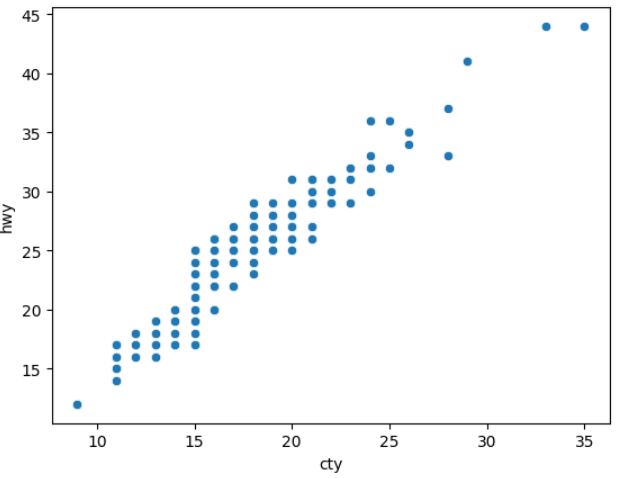
21) 어떤 회사에서 생산한 'suv' 차종의 도시 연비가 높은지 알아보려고 합니다. suv 차종을 대상으로 cty 평균이 가장 높은 회사 다섯곳을 막대그래프로 표현해보세요. 막대는 연비가 높은 순으로 정렬하세요.
##집단별 제조사별 cty 평균연비표 만들기
df_cty=df.query(' category == "suv" ').groupby('manufacturer',as_index=False).agg( mean_cty = ('cty','mean') ).sort_values('mean_cty',ascending=False)
df_cty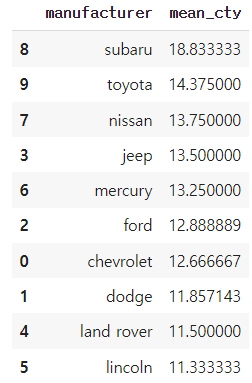
# 상위 5개 회사 그래프 그리기
df_top_5=df_cty.head(5)
sns.barplot(data=df_top_5 , x='manufacturer' ,y='mean_cty')
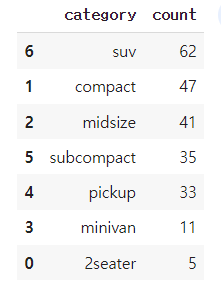
22) 자동차 중에 어떤 category가 많은 지 알아보려고 합니다. sns.barplot()을 이용해 자동차 종류별 빈도를 표현한 막대 그래프를 만들어 보세요. 막대는 빈도가 높은 순으로 정렬하세요.
# category별 count 표만들기
df_category=df.groupby('category',as_index=False).agg(count=('category','count')).sort_values('count',ascending=False)
df_category
# 그래프 그리기
sns.barplot(data=df_category, x='category' , y='count')
## count plot을 이용해서 만들기
# 빈도가 높은 순서대로 index 구하기
index=df['category'].value_counts().index
sns.countplot(data=df , x='category', order=index)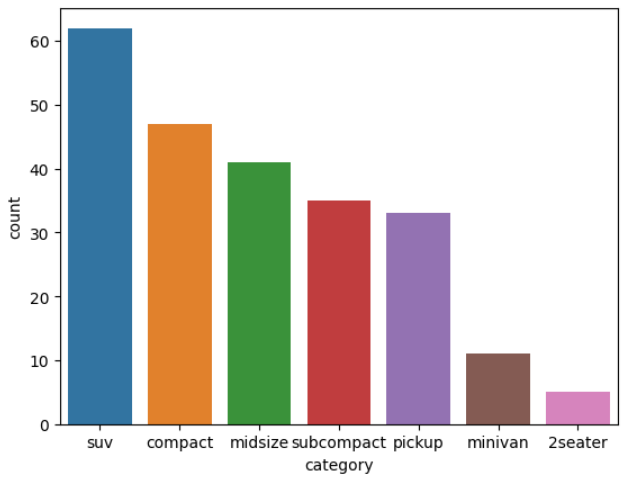
## 여기서는 economics 데이터사용
23) psavert(개인 저축률)가 시간에 따라 어떻게 변해 왔는 지 알아보려고 합니다. 연도별 개인 저축률의 변화를 나타낸 시계열 그래프로 만들어보세요.
## 연도별 개인 저출율 변화
# date datetime 형태로 변경
df['date']=pd.to_datetime(df['date'])
df.info()
# 연도별 개인 저축율 변화확인
sns.lineplot(data=df, x=df['date'].dt.year , y='psavert', ci=None)
24) 2014년 월별 psavert의 변화를 나타낸 시계열 그래프를 만들어보세요.
#2014년 월별그래프
# year / month 데이터 만들기
df['month']=df['date'].dt.month
df['year']=df['date'].dt.year
df
# 2014년 데이터 가져오기
df_2014=df.query('year == 2014')[['month','psavert']]
# 그래프 그리기
sns.lineplot(data=df_2014 , x='month' ,y='psavert' , ci =None)
25) category 가 'compact' , 'subcompact' , 'suv' 인 자동차의 cty가 어떻게 다른지 비교해 보려고 합니다. 세 차종의 cty를 나타낸 상자 그림을 만들어보세요.
## category내에 해당하는 차량추출
df_category=df.query('category in ["suv" , "compact" , "subcompact"]')
#그래프 그리기
sns.boxplot(data=df_category , x='category' ,y='cty')
'Python 데이터분석' 카테고리의 다른 글
| [데이터분석실습]텍스트 마이닝_대통령 연설문 분석 (0) | 2022.06.26 |
|---|---|
| [데이터분석정리_2] 그래프 그리기 (0) | 2022.06.24 |
| [데이터분석_정리_1]query() / sort_values() / assign() / groupby() / agg() / merge() / concat() (0) | 2022.06.21 |
| [데이터분석실습] 미국 동북중부_midwest 정보 확인 (np.where / value_counts / sort_index) (0) | 2022.06.19 |
| [seaborn] titanic 그래프 그리기 && pydataset 활용 (0) | 2022.06.19 |


