
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Instagrame clone
- 조코딩
- TeachagleMachine
- 강화학습
- 카트폴
- FirebaseV9
- 강화학습 기초
- 앱개발
- clone coding
- 머신러닝
- 리액트네이티브
- kaggle
- coding
- Reinforcement Learning
- 사이드프로젝트
- Ros
- pandas
- JavaScript
- App
- 클론코딩
- expo
- redux
- 전국국밥
- React
- python
- selenium
- ReactNative
- GYM
- 딥러닝
- 데이터분석
- Today
- Total
qcoding
[데이터분석실습]통계 분석 기법을 이용한 가설검정 본문
https://github.com/youngwoos/Doit_Python/tree/main/Data
GitHub - youngwoos/Doit_Python: <Do it! 쉽게 배우는 파이썬 데이터 분석> 저장소
<Do it! 쉽게 배우는 파이썬 데이터 분석> 저장소. Contribute to youngwoos/Doit_Python development by creating an account on GitHub.
github.com
## 가설검증
1) 기술통계 (Descriptive statistics)
--> 데이터를 요약해 설명하는 통계 분석 기법
ex) 사람들이 받는 월급을 집계해 전체 월급 평균을 구함
2) 추론통계 (Inferential statisctics)
--> 어떤 값이 발생활 확률을 계산하는 통계 분석 기법
ex) 데이터에서 성별에 따라 월급에 차이가 있는 것으로 나타났을때, 이런차이가 우연히 발생활 확률을 계산함.
- 우연히 나타날 확률이 작다면 --> 통계적으로 유의하다 (staticstically significant)
- 우연히 나타날 확률이 크다면 --> 통계적으로 유의하지 않다. (not statistically significant)
3) 통계적 가설 검증 (statistical hypothesis test)
-> 유의확률을 이용해 가설을 검정하는 방법
-> 유의확률 (significance probability , p-value) : 실제로는 집단 간 차이가 없는 데 우연히 차이가 있는 확률
유의확률 (p-value) > 0.05 (5%) 기준 => 유의하지 않다.
t 검정 ( 집단의 평균에 차이가 있는지 검정)
# mpg 데이터를 이용해 'compact' 자동차와 'suv' 자동차의 도시 연비 차이가 통계적으로 유의한 지호가인
import pandas as pd
df=pd.read_csv('./mpg.csv')
df
# 기술통계분석
df.query('category in ["compact" , "suv"]').groupby('category',as_index=False).agg(
count=('category','count'),
mean_cty=('cty','mean')
)
# 평균의 차이가 유의한 지 t 검정을 수행
-> 집단간 분산이 같다고 가정하고 equal_var = True
#변수할당
compact = df.query('category == "compact"')['cty']
suv= df.query('category =="suv"')['cty']
# t-test
from scipy import stats
stats.ttest_ind(compact,suv,equal_var=True)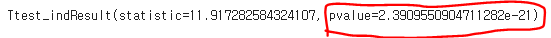
p-value < 0.05 (%) 작으므로 --> 'compact' 와 'suv' 평균 도시 연비 차이가 통계적으로 유의하다.
# 일반 휘발유와 고급 휘발유의 도시 연비
# 기술통계분석
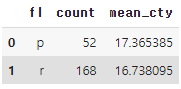
df.query('fl in ["r" , "p"]').groupby('fl',as_index=False).agg(
count=('fl','count'),
mean_cty=('cty','mean')
)
# 변수 할당
re=df.query('fl == "r"')['cty']
pre=df.query('fl == "p"')['cty']
# t-test
from scipy import stats
stats.ttest_ind(re,suv,equal_var=True)
p-value < 0.05 (%) 작으므로 --> 'regular' 와 'premium' 평균 도시 연비 차이가 통계적으로 유의하다.
상관분석 - 두 변수의 관계 분석하기
# economics 데이터를 이용하여 unemploy (실업자 수) 와 pce (개인 소비 지출) 간에 상관관계가 있는 지 확인
1) 상관계수 구하기
df=pd.read_csv('./economics.csv')
df
# 상관 행렬 만들기
df[['unemploy','pce']].corr()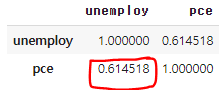
0.61 이므로 비례관계를 의미한다.
2) 유의확률 구하기
-> 상관관계 / 유의확률 동시에 구하기
stats.pearsonr(df['unemploy'] , df['pce'])
앞에 0.61 은 상관관계 이며 , 두번째 6.77e-61 은 유의확률을 의미함.
유의확률 ( p-value) < 0.05 (%) => 통계적으로 유의하다.
상관분석 - 히트맵 만들기
## 여러변수의 관련성을 한꺼번에 알아보기 위해 상관행렬 (coreeleation matrix)를 통한 분석
# 상관행렬만들기
df=pd.read_csv('./mtcars.csv')
df.head()
# 상관행렬 만들고 , 소수점 둘째 자리까지 반올림
df_cor=df.corr()
df_cor=round(df_cor,2)
df_cor
-> 상관관계가 양수일 경우 비례 관계이며, 음수일 경우 반비례 관계로 추측할 수있음
#히트맵 만들기
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams.update({
'figure.dpi' : '120',
'figure.figsize': [7.5,5.5]
})
## 히트맵 만들기
sns.heatmap(
df_cor,
# 상관계수 표시
annot=True,
# 컬러맵
cmap='RdBu'
)
-> 관계성이 높을 수록 짙은 파란색을 띄고, 낮을 수록 짙은 빨간색을 띄게됨.
#대각행렬 제거하기
-> df_cor 히트맵과 동일한 0으로 채워진 mask 배열을 생성함
# 대각행렬 제거하기
import numpy as np
mask = np.zeros_like(df_cor)
mask
# mask 위 대각행렬을 1로 만듬
mask[np.triu_indices_from(mask)]=1
mask
## 히트맵에 mask 적용하기
## 히트맵 만들기
sns.heatmap(
df_cor,
# 상관계수 표시
annot=True,
# 컬러맵
cmap='RdBu',
mask=mask
)
위에서 mpg 의 맨 첫 행과 / carb의 맨 끝 열은 빈값이므로 제거함
# 행 / 열 보정
# mask 보정
mask=mask[1:,:-1]
# corr 행렬 보정
df_cor=df_cor.iloc[1:,:-1]
## 히트맵 만들기
sns.heatmap(
df_cor,
# 상관계수 표시
annot=True,
# 컬러맵
cmap='RdBu',
mask=mask,
linewidths=0.5,
# 최대값 대체
vmax=1,
# 최소값 대체
vmin=-1,
# 범례크기 줄이기
cbar_kws={"shrink" :0.5}
)
'Python 데이터분석' 카테고리의 다른 글
| [데이터전처리]LabelEncoding / OneHotEncoding (0) | 2022.06.29 |
|---|---|
| [데이터분석실습][이진분류_결정트리]소득 예측 모델 만들기 (0) | 2022.06.28 |
| [데이터분석실습]인터랙티브 그래프 (0) | 2022.06.28 |
| [데이터분석실습]지도 시각화 (0) | 2022.06.28 |
| [데이터분석실습]기사 댓글 텍스트 마이닝 (0) | 2022.06.27 |



