
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- FirebaseV9
- 카트폴
- kaggle
- 딥러닝
- Instagrame clone
- ReactNative
- 강화학습
- pandas
- expo
- App
- 클론코딩
- 강화학습 기초
- 리액트네이티브
- 조코딩
- JavaScript
- GYM
- 사이드프로젝트
- 전국국밥
- React
- 머신러닝
- Ros
- TeachagleMachine
- redux
- python
- clone coding
- 데이터분석
- 앱개발
- Reinforcement Learning
- selenium
- coding
- Today
- Total
qcoding
[GAN]1D 그래프 생성하기_BASE 본문
* 본실습은 딥러닝 생성모델인 GAN에 대한 간단한 실습이다. 향후에 GAN을 이용하여 시계열 데이터를 생성하는 실습을 진행예정으로 이를 준비하기 위해서 GAN의 간단한 코드를 구현해 보는 실습을 하였다.
해당 실습은 아래의 코드를 보고 진행하였다.
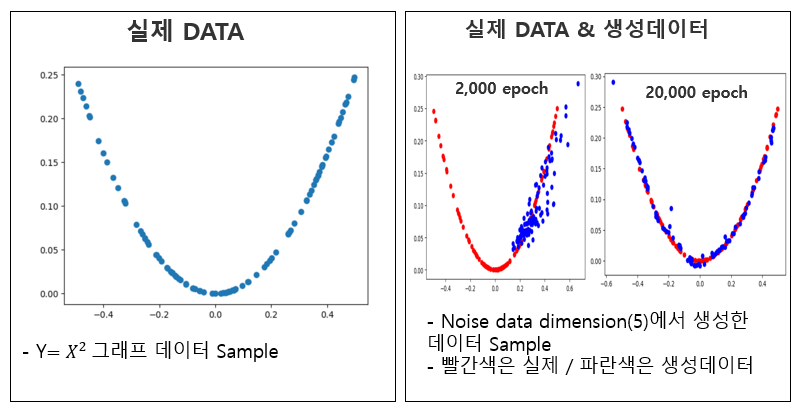
이번 실습의 내용을 정리하면 y=x^2에 해당하는 data sample을 가지고 학습시켜 실제와 비슷한 분포를 지닌 가짜 sample을 만드는 것으로 epoch가 진행됨에 따라 실제 data 와 유사해 지는 것을 볼 수 있다.
1) GAN 모델이란?
GAN에 대한 간단한 설명을 하면 아래와 같다. GAN은 Generative Adversarial Network의 약자로, 딥러닝 모델 중 하나이며, 생성 모델 중 하나이다. GAN은 생성자(generator)와 판별자(discriminator)라는 두 개의 네트워크를 가지고 있어. 생성자는 랜덤한 잡음 벡터(noise vector)를 입력으로 받아 가짜 데이터(fake data)를 생성하고, 판별자는 이 가짜 데이터와 진짜 데이터(real data)를 구분하는 역할을 한다. 이 두 네트워크는 경쟁적인 학습을 통해 서로를 발전시키며, 생성자는 진짜 데이터와 구분할 수 없는 가짜 데이터를 생성할 수 있게 된다.
간단히 말하면, GAN은 생성 모델 중 하나로서, 랜덤한 잡음 벡터를 입력으로 받아 가짜 데이터를 생성하고, 이를 진짜 데이터와 구분할 수 있는 판별자와 경쟁하면서 점점 더 나은 결과를 만들어내는 딥러닝 모델이다. 이러한 GAN은 이미지 생성, 음악 생성, 자연어 처리 등 다양한 분야에서 활용되고 있다.
2) GAN 모델의 예시
GAN에서 유명한 모델로는 DCGAN(Deep Convolutional GAN), CycleGAN, StyleGAN 등이 있다.
DCGAN은 이미지 생성 분야에서 가장 많이 사용되는 GAN 모델 중 하나이다. 이 모델은 Convolutional Neural Network를 사용하여 이미지를 생성하며, 생성자와 판별자 모두 CNN을 사용한다. 이 모델은 이미지 생성 분야에서 좋은 성능을 보이고 있으며, 높은 해상도의 이미지 생성에도 효과적이다.
CycleGAN은 이미지 변환 분야에서 사용되는 GAN 모델 중 하나이다. 이 모델은 한 도메인에서 다른 도메인으로 이미지를 변환하는 것을 목표로 한다. 예를 들어, 말 이미지를 얼룩말 이미지로 변환하는 것과 같은 작업을 수행할 수 있다. 이 모델은 데이터 쌍(pair)을 필요로 하지 않고, 자연스러운 이미지 변환을 가능하게 한다.
StyleGAN은 이미지 생성 분야에서 가장 최신 기술 중 하나이다. 이 모델은 이전 모델들보다 더 자연스러운 이미지를 생성할 수 있으며, 생성된 이미지에 대한 조작성(manipulability)이 뛰어나다. 이 모델은 이미지 생성 분야에서 높은 성능을 보이고 있으며, 인공지능 캐릭터나 가상 인테리어 등을 생성하는데 활용된다.
이외에도 GAN 모델 중 다른 유명한 예로는 WGAN(Wasserstein GAN), GPT-2(Generative Pre-trained Transformer 2), BigGAN 등이 있다.
WGAN은 GAN 모델에서 발생하는 학습 불안정성 문제를 개선하기 위해 제안된 모델 중 하나이다. 이 모델은 경사 하강법(gradient descent) 대신 Wasserstein 거리(Wasserstein distance)를 사용하여 생성자와 판별자를 학습시키는 방식을 사용한다. 이를 통해 GAN 모델이 더 안정적으로 학습되고, 높은 품질의 이미지를 생성할 수 있다.
GPT-2는 자연어 처리 분야에서 사용되는 GAN 모델 중 하나이다. 이 모델은 대규모 텍스트 데이터를 사용하여 사전 학습된(pre-trained) 모델로, 다양한 자연어 처리 작업에 적용될 수 있다. GPT-2는 다양한 길이의 텍스트를 생성하며, 대화 시스템, 기사 생성 등 다양한 분야에서 활용되고 있다.
BigGAN은 이미지 생성 분야에서 매우 큰 모델을 사용하여 고품질 이미지를 생성하는데 특화된 GAN 모델 중 하나이다. 이 모델은 GAN의 생성자와 판별자 모두 매우 큰 모델을 사용하며, 이미지 생성 분야에서 가장 높은 해상도와 질을 가진 이미지를 생성할 수 있다.
3) GAN 실습내용 정리
* 본실습은 크게 2가지로 되어있다.
3-1) Discriminator(판별자) 학습을 먼저 하고 GAN모델에서는 Generator(생성자)만 학습하고 판별자는 미리 학습된 모델을 사용하는 방법이다.
--> GAN 모델은 판별자와 생성자의 적대적 학습으로 전체적으로 학습이 잘되기 위해서는 판별자와 생성자의 학습정도에 따라 적절하게 업데이트를 수행하는 것이 필요하다. 예를들어 Discriminator가 가짜 샘플을 잘 찾아낼 때 Generator는 더 많이 업데이트하고, Discriminator 모델이 가짜 샘플을 탐지할 때 상대적으로 좋지 않거나 혼란스러울 때는 Generator 모델을 적게 업데이트해야한다.
3-2) Discriminator(판별자)와 Generator(생성자)를 동시에 학습하는 것이다.
--> 두번째는 판별자와 생성자모델 둘다 동시에 업데이트 하는 것이다. 그러나 코드에서 보면
# determine half the size of one batch, for updating the discriminator
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_epochs):
### DISCRIMINATOR 모델 학습
# prepare real samples
x_real, y_real = generate_real_samples(half_batch)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator
d_model.train_on_batch(x_real, y_real)
d_model.train_on_batch(x_fake, y_fake)
### GAN 모델
x_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = ones((n_batch, 1))
# update the generator via the discriminator's error
gan_model.train_on_batch(x_gan, y_gan)discriminator인 d_model을 학습할때는 half_batch 로 적은 수의 실제 데이터와, 가짜 데이터를 생성하여 업데이트를 진행하고 Gan의 전체 모델은 batch로 더 많은 수의 샘플을 generator로 생성하고, discriminator로 판별하는 것을 볼 수 있다. 즉, generator더 더 많은 학습을 하게하고, 판별모델은 더 적은 수를 학습하게 하여 generator의 성능지표를 고정하는 동시에 성능이 좀올라올 때까지 기다려 주는 것을 의미한다. GAN 모델은 이와 같이 학습을 잘 수렴하기 위하여 여러 방법을 사용해 주어야 한다는 것을 배웠다.
4) GAN 실습
1) Discriminator학습 -> GAN 모델 생성 -> Generator 학습
### 판별 모델 설정
# define the standalone discriminator model
### 여기서 n_inputs가 들어오는 input shpae을 의미함 (batch_size, n_inputs) => (NONE,n_inputs)
def define_discriminator(n_inputs=2):
input_size = keras.layers.Input(shape=(n_inputs,))
x=Dense(25, activation='relu', kernel_initializer='he_uniform')(input_size)
output=Dense(1, activation='sigmoid')(x)
# compile model
model = keras.models.Model(inputs=[input_size], outputs=[output])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
model = define_discriminator()
model.summary()
# plot the model
plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True)
def generate_real_samples(n):
# generate inputs in [-0.5, 0.5]
X1 = rand(n) - 0.5
# generate outputs X^2
X2 = X1 * X1
# stack arrays
X1 = X1.reshape(n, 1)
X2 = X2.reshape(n, 1)
X = hstack((X1, X2)) ### X는 [X,X^2]의 형태를 N개의 sample을 이어 붙인 형태(axis=0)
# generate class labels
y = ones((n, 1)) ### y는 실제값에 대한 label로 sample의 갯수 만큼 [1] 로 되어 있는 형태
return X, y
# generate n fake samples with class labels
def generate_fake_samples(n):
# generate inputs in [-1, 1]
X1 = -1 + rand(n) * 2
# generate outputs in [-1, 1]
X2 = -1 + rand(n) * 2
# stack arrays
X1 = X1.reshape(n, 1)
X2 = X2.reshape(n, 1)
X = hstack((X1, X2)) ### X는 [X,X]의 형태를 N개의 sample을 이어 붙인 형태(axis=0) -> 가짜 데이터
# generate class labels
y = zeros((n, 1))
return X, y
### 판별자 학습
# train the discriminator model
def train_discriminator(model, n_epochs=1000, n_batch=128):
half_batch = int(n_batch / 2)
# run epochs manually
for i in range(n_epochs):
# generate real examples
X_real, y_real = generate_real_samples(half_batch) ### X_real_shape (half_batch, 2) -> 2는 feature 수 [x,x^2]
# update model
model.train_on_batch(X_real, y_real)
# generate fake examples
X_fake, y_fake = generate_fake_samples(half_batch) ### X_fake_shape (half_batch, 2) -> 2는 feature 수 [x,x]
# update model
model.train_on_batch(X_fake, y_fake)
# evaluate the model
_, acc_real = model.evaluate(X_real, y_real, verbose=0)
_, acc_fake = model.evaluate(X_fake, y_fake, verbose=0)
if i % 100 == 0:
print(f'epoch : {i+1}, acc_real : {round(acc_real,2)*100}%, acc_fake : {round(acc_fake,2)*100}%')
# define the discriminator model
model = define_discriminator()
# fit the model
train_discriminator(model)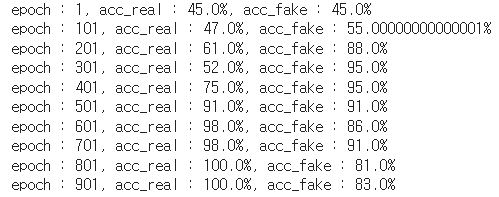
### 생성기모델
# define the standalone generator model
def define_generator(latent_dim, n_outputs=2):
model = Sequential()
model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim))
model.add(Dense(n_outputs, activation='linear'))
return model
### GAN모델
# define the combined generator and discriminator model, for updating the generator
def define_gan(generator, discriminator):
# make weights in the discriminator not trainable
discriminator.trainable = False
# connect them
model = Sequential()
# add generator
model.add(generator)
# add the discriminator
model.add(discriminator)
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam')
return model--> 여기서는 discriminaotr.trainable = Falseㄹ 설정하여 판별자는 학습이 되지 않도록 하였다. 학습에는 앞에서 미리 학습한 판별자를 사용하였다.
### 모델학습
def train_gan(gan_model, latent_dim, n_epochs=10000, n_batch=128):
# manually enumerate epochs
for i in range(n_epochs):
# prepare points in latent space as input for the generator
x_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = ones((n_batch, 1))
# update the generator via the discriminator's error
gan_model.train_on_batch(x_gan, y_gan)--> generator로 생성한 모델 값은 생성자 입장에서는 항상 실제 data label=1로 생성해야 하므로 y_gan 값은 항상 1(실제)가 된다.
위와 같이 학습하면 GAN모델에서는 Generator만 학습되므로, discriminator는 generator가 학습이 되면 주기적으로 다시 업데이트를 시켜서 적용해야 한다. 이러한 번거로움을 없애고자 아래와 같이 GAN 한 모델 내에서 판별자와 생성자를 동시에 업데이트 하도록 학습함수를 수정한다.
2) Discriminator & Generator 학습 (* 전체코드)
######### 전체모델
### discriminator는 half batch로 조금만 업데이트 시키고
### generator는 batch로 많은 샘플을 생성함.
### 이는 discriminator를 학습을 덜 시키고 generator 학습을 많이시켜서
### generator 가 학습이 잘되게 하기 위함임
from numpy import hstack
from numpy import zeros
from numpy import ones
from numpy.random import rand
from numpy.random import randn
from keras.models import Sequential
from keras.layers import Dense
from matplotlib import pyplot
# define the standalone discriminator model
def define_discriminator(n_inputs=2):
model = Sequential()
model.add(Dense(25, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs))
model.add(Dense(1, activation='sigmoid'))
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# define the standalone generator model
def define_generator(latent_dim, n_outputs=2):
model = Sequential()
model.add(Dense(15, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim))
model.add(Dense(n_outputs, activation='linear'))
return model
# define the combined generator and discriminator model, for updating the generator
def define_gan(generator, discriminator):
# make weights in the discriminator not trainable
discriminator.trainable = False
# connect them
model = Sequential()
# add generator
model.add(generator)
# add the discriminator
model.add(discriminator)
# compile model
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
# generate n real samples with class labels
def generate_real_samples(n):
# generate inputs in [-0.5, 0.5]
X1 = rand(n) - 0.5
# generate outputs X^2
X2 = X1 * X1
# stack arrays
X1 = X1.reshape(n, 1)
X2 = X2.reshape(n, 1)
X = hstack((X1, X2))
# generate class labels
y = ones((n, 1))
return X, y
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n):
# generate points in the latent space
x_input = randn(latent_dim * n)
# reshape into a batch of inputs for the network
x_input = x_input.reshape(n, latent_dim)
return x_input
# use the generator to generate n fake examples, with class labels
def generate_fake_samples(generator, latent_dim, n):
# generate points in latent space
x_input = generate_latent_points(latent_dim, n)
# predict outputs
X = generator.predict(x_input,verbose=0)
# create class labels
y = zeros((n, 1))
return X, y
# evaluate the discriminator and plot real and fake points
def summarize_performance(epoch, generator, discriminator, latent_dim, n=100):
# prepare real samples
x_real, y_real = generate_real_samples(n)
# evaluate discriminator on real examples
_, acc_real = discriminator.evaluate(x_real, y_real, verbose=0)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(generator, latent_dim, n)
# evaluate discriminator on fake examples
_, acc_fake = discriminator.evaluate(x_fake, y_fake, verbose=0)
# summarize discriminator performance
print(epoch, acc_real, acc_fake)
# scatter plot real and fake data points
pyplot.scatter(x_real[:, 0], x_real[:, 1], color='red')
pyplot.scatter(x_fake[:, 0], x_fake[:, 1], color='blue')
pyplot.show()
# train the generator and discriminator
def train(g_model, d_model, gan_model, latent_dim, n_epochs=20000, n_batch=128, n_eval=2000):
# determine half the size of one batch, for updating the discriminator
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_epochs):
# prepare real samples
x_real, y_real = generate_real_samples(half_batch)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator
d_model.train_on_batch(x_real, y_real)
d_model.train_on_batch(x_fake, y_fake)
# prepare points in latent space as input for the generator
x_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = ones((n_batch, 1))
# update the generator via the discriminator's error
gan_model.train_on_batch(x_gan, y_gan)
# evaluate the model every n_eval epochs
if (i+1) % n_eval == 0:
summarize_performance(i, g_model, d_model, latent_dim)
# size of the latent space
latent_dim = 5
# create the discriminator
discriminator = define_discriminator()
# create the generator
generator = define_generator(latent_dim)
# create the gan
gan_model = define_gan(generator, discriminator)
# train model
train(generator, discriminator, gan_model, latent_dim)--> 위의 코드를 생성하면 2000 epoch 마다 그래프가 plot되고 값을 확인 할 수 있다.
여기서 보면 epoch가 증가할 수록 실제 값과 유사하게 되지만, 생각해보면 학습이 진행된다고 해서 값이 일정하게 개선된다고 보장하지는 않는 것 같다. 앞선 강화학습에서도 학습된 값이 Monotonic(단조증가) 되지 않는 문제가 있어서 이를 해결하기 위한 여러 방법 (TRPO, PPO)등이 있었는데, 아직 공부 초기라 정확하게 모르겠지만 GAN에서도 이러한 방법들이 있을 것 같다고 생각이 된다. GAN에 대하여 좀 더 학습해 보아야 겠다.
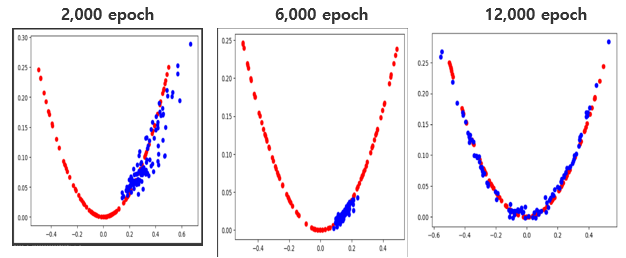
** 아래는 추가로 Y=X^2이 아닌 좀 더 어려운 SIN함수를 학습하는 것으로 코드를 변경하였을때의 예시이다.

--> SIN 함수가 좀더 어렵다고는 하지만 생각보다 생성이 잘 안되는 것 같다. 판별자와 생성자의 Depth가 작기도 하고 단순 실습인 코드이기 때문에 위와 같은 결과가 나온 것 같다. 다음에는 좀더 복잡한 문제를 접근하는 실습을 진행해보아야 겠다.
## 전체코드
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential, Model
from keras.layers import Dense, Input, LeakyReLU
from keras.optimizers import Adam
def build_generator(latent_dim):
model = Sequential()
model.add(Dense(10, input_dim=latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(2, activation='tanh'))
return model
def build_discriminator():
model = Sequential()
model.add(Dense(10, input_dim=2))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
return model
def generate_real_samples(n):
X1 = np.random.rand(n) * 4 - 2
X2 = np.sin(X1 * np.pi)
X1 = X1.reshape(n, 1)
X2 = X2.reshape(n, 1)
X = np.hstack((X1, X2))
y = np.ones((n, 1))
return X, y
def generate_latent_points(latent_dim, n):
x_input = np.random.randn(latent_dim * n)
x_input = x_input.reshape(n, latent_dim)
return x_input
def generate_fake_samples(generator, latent_dim, n):
x_input = generate_latent_points(latent_dim, n)
X = generator.predict(x_input,verbose=0)
y = np.zeros((n, 1))
return X, y
def build_gan(generator, discriminator):
discriminator.trainable = False
gan_input = Input(shape=(latent_dim,))
x = generator(gan_input)
gan_output = discriminator(x)
gan = Model(inputs=gan_input, outputs=gan_output)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return gan
# evaluate the discriminator and plot real and fake points
def summarize_performance(epoch, generator, discriminator, latent_dim, n=100):
# prepare real samples
x_real, y_real = generate_real_samples(n)
# evaluate discriminator on real examples
_, acc_real = discriminator.evaluate(x_real, y_real, verbose=0)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(generator, latent_dim, n)
# evaluate discriminator on fake examples
_, acc_fake = discriminator.evaluate(x_fake, y_fake, verbose=0)
# summarize discriminator performance
print(epoch, acc_real, acc_fake)
# scatter plot real and fake data points
pyplot.scatter(x_real[:, 0], x_real[:, 1], color='red')
pyplot.scatter(x_fake[:, 0], x_fake[:, 1], color='blue')
pyplot.show()
# train the generator and discriminator
def train(g_model, d_model, gan_model, latent_dim, n_epochs=20000, n_batch=128, n_eval=2000):
# determine half the size of one batch, for updating the discriminator
half_batch = int(n_batch / 2)
# manually enumerate epochs
for i in range(n_epochs):
# prepare real samples
x_real, y_real = generate_real_samples(half_batch)
# prepare fake examples
x_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
# update discriminator
d_model.train_on_batch(x_real, y_real)
d_model.train_on_batch(x_fake, y_fake)
# prepare points in latent space as input for the generator
x_gan = generate_latent_points(latent_dim, n_batch)
# create inverted labels for the fake samples
y_gan = ones((n_batch, 1))
# update the generator via the discriminator's error
gan_model.train_on_batch(x_gan, y_gan)
# evaluate the model every n_eval epochs
if (i+1) % n_eval == 0:
summarize_performance(i, g_model, d_model, latent_dim)
# size of the latent space
latent_dim = 5
# create the discriminator
discriminator = define_discriminator()
# create the generator
generator = define_generator(latent_dim)
# create the gan
gan_model = define_gan(generator, discriminator)
# train model
train(generator, discriminator, gan_model, latent_dim)
'머신러닝 딥러닝' 카테고리의 다른 글
| [window & 아나콘다 & 텐서플로 GPU] 설치하는 방법 (1) | 2024.01.21 |
|---|---|
| [kaggle]2진 분류 코드 - KernerelPCA / GMM / HIST FEATURE / STACKING (0) | 2023.12.12 |
| [강화학습] DDPG (Deep Deterministic Policy Gradient)실습_ContinuosMountainCar(2/2) (0) | 2023.03.15 |
| [강화학습] DDPG (Deep Deterministic Policy Gradient) 강화학습 (1/2)_이론 (1) | 2023.03.11 |
| [강화학습]A3C_Continuos Actor_Critic_MountainCar (0) | 2023.02.28 |



