
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- coding
- JavaScript
- GYM
- 앱개발
- 카트폴
- python
- 조코딩
- 강화학습
- Instagrame clone
- Ros
- App
- 전국국밥
- React
- 클론코딩
- ReactNative
- pandas
- 강화학습 기초
- 머신러닝
- FirebaseV9
- 리액트네이티브
- kaggle
- 데이터분석
- TeachagleMachine
- expo
- 딥러닝
- selenium
- redux
- Reinforcement Learning
- clone coding
- 사이드프로젝트
- Today
- Total
qcoding
[강화학습] DDPG (Deep Deterministic Policy Gradient) 강화학습 (1/2)_이론 본문
* 이번에 살펴볼 내용은 DDPG에 대한 내용이다. DDPG (Deep Deterministic Policy Gradient)의 약어로 "확정적 Policy"를 사용하는 알고리즘이다. 이번에는 글을 2개로 나누어서 작성할 예정이며, 첫번째는 이론을 살펴보고 두번째로 실습을 진행하려고 한다.
* 해당 내용은 아래의 유튜브를 보고 참고하여 작성하였습니다. 고려대학교 오승상 교수님의 유튜브인데 설명을 매우 잘해주셔서 이해가 잘되었습니다. 글에서 나오는 PPT는 교수님께서 올려주신 파일의 일부분을 사용하였습니다.
https://www.youtube.com/playlist?list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC
오승상 강화학습 Deep Reinforcement Learning
고려대학교 오승상 교수의 강화학습 Deep Reinforcement Learning 강의 입니다. (자료) https://sites.google.com/view/seungsangoh
www.youtube.com
1) DDPG 알고리즘 생성 배경
-> 강화학습의 분류를 보면 크게 2가지 갈래인 Value Based와 Policy Based 알고리즘이 있으며, 2가지 알고리즘을 결합한 Actor Critic 알고리즘이 존재한다.
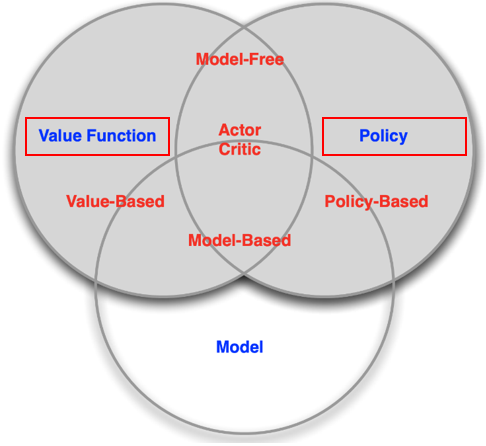
Value Based는 이름 그대로 Value Functon (가치함수)를 기반으로 Optimal Policy (최적정책)을 찾아가는 방법이다. 가치함수를 통해서 action을 선택하기 때문에 Policy가 존재하지 않으며, implicit policy (암묵적인) 정책을 사용한다.
Policy Based는 Policy 자체를 강화하는 알고리즘으로 explicit policy (명확한) 정책이 존재하며, 에피소드를 진행하면서 받는 return으로 이 action이 좋은 것인지 안좋은 것인지를 판단하여 Action Distribution을 변경해 나간다.

Actor Critic은 위의 2가지 방법론을 합친 것으로 Policy를 통해 action 자체를 강화하는 Policy-based 방법론을 사용하는 Actor network와 수행한 Action의 가치를 판단하는 Value-based방법론을 사용하는 Critic Network로 이루어져 있다.
이렇게 각각 다른 방법론을 사용하는 여러 알고리즘들이 발전해온 과정을 살펴보면 아래와 같다.
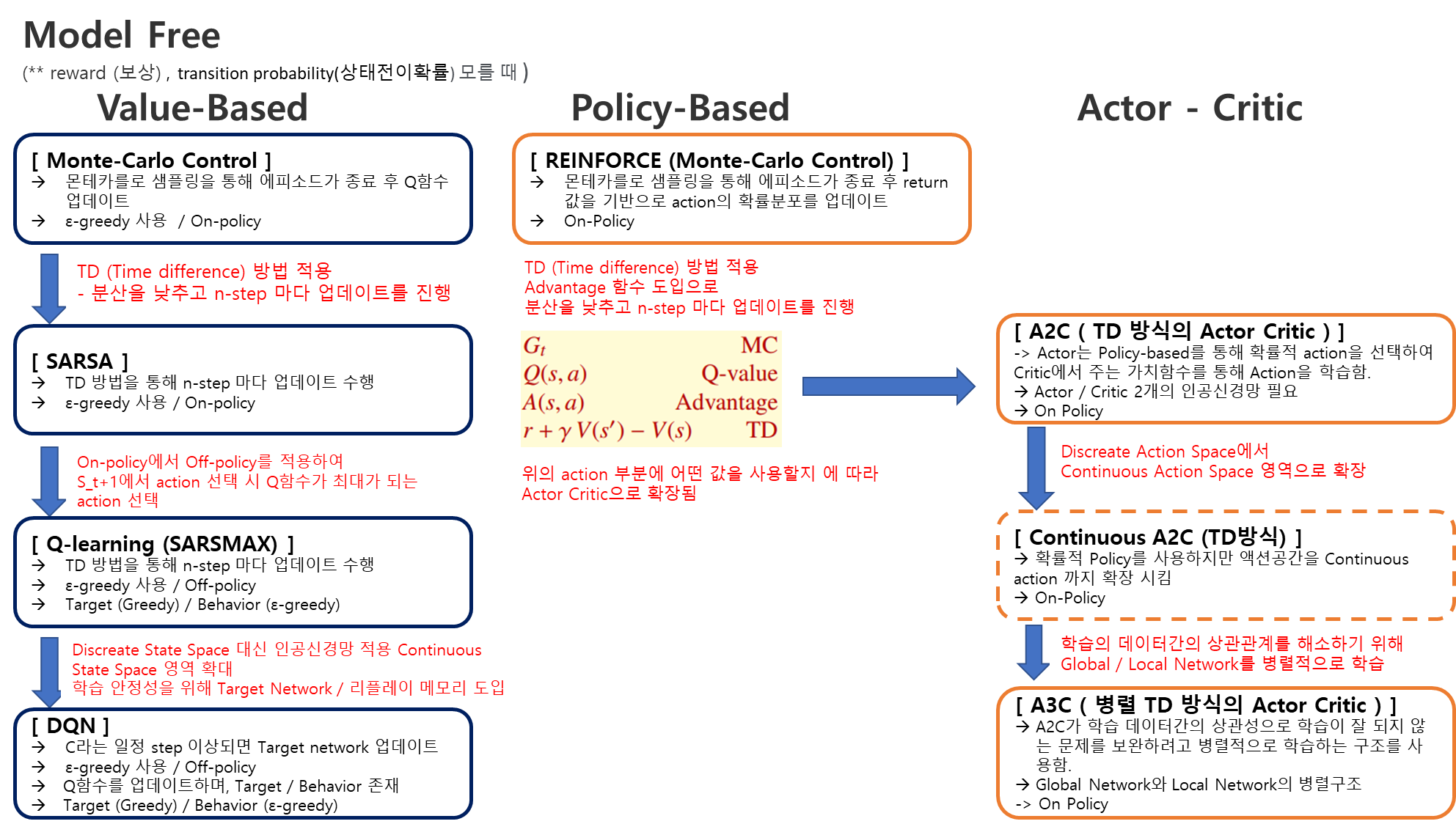
기본적으로 위의 알고리즘들이 발전해 나가는 과정을 크게 3가지의 측면에서 볼 수 있을 것 같다.
( * 주관적인 생각으로 3가지를 정리하였습니다.)
1) 학습의 수렴성을 위해 Variance를 낮추는 방향
--> Monte-carlo 에서 Q함수(액션가치함수) 업데이트 사용하는 return은 정의에 따라서 액션가치함수의 불편추정량(unbiased estimate)값으로 편향(bias)은 보장되지만, 에피소드까지 도착할 때의 경로가 너무 다양하여 큰 variance를 갖게 된다. 그러므로 매 스텝마다 Q함수(가치함수)를 업데이트 할 수 있는 TD (Time Difference)방법을 사용하는 쪽으로 변경해져 갔다.
2) 상태공간의 확장 (Discreate -> Continuos)
--> 강화학습에서 Q함수 / Policy 의 분포에 인공신경망을 사용하여 상태공간이 확장되는 방향으로 발전하였다. 알고리즘의 초기에는 대부분 작은 State Space를 가지기 때문에 테이블에 상태를 표시하여 업데이는 하는 방법을 사용해도 크게 무리가 없었다. 그러나 실생활에서 볼 수 있는 문제를 풀기 위해서는 상태공간의 확장이 필요하며 이를 이용하여 인공신경망을 도입하여 한정된 State Space에서 Continuos State Space로 확장하였다. 위에서 Continuos A2C를 제외하면 아직 ACTION에 대해서는 이산적인 상태공간을 가지고 있으며, 이것을 ACTION까지 확장한 것이 이번에 설명할 DDPG 이다.
3) Sequential 한 환경에서 오는 학습 데이터간의 상관관계(correlation)의 문제를 해결하는 방향
--> 강화학습은 Env에 오는 데이터가 순차적인 상관관계 (sequential)를 가지고 있는 데이터이다. 사실 강화학습의 문제를 정의하는 MDP 자체가 순차적인 문제만 적용가능하기 때문에 당연한 얘기이지만, 이러한 학습 데이터간의 상관관계로 인하여 학습이 잘 되지 않는 경우가 많다. 이를 해소하려고 사용한 것이 Off-policy 알고리즘인 DQN에서 사용하는 리플레이 메모리이며, On-policy 알고리즘인 A3C에서 사용하는 병렬적 구조이다.
위의 내용을 정리하면 다양한 알고리즘이 발전되는 방향은 크게 3가지로 학습의 수렴성을 낮추고, 상태공간을 확장하며 학습데이터간의 상관관계를 해소하는 방향으로 발전하였다. DDPG 역시 이와 같은 방향성을 가지고 있으며 특히 상태공간을 확장했다는 측면이 가장 중요한 것 같다.
2) DDPG 이론 소개

위의 문장이 DDPG를 잘 나타내는 문장으로 위에 표현된 내용에 대해서 한번 세부적으로 살펴보도록 하자.
① Actor - Critic
--> DDPG의 형태는 Actor - Critic을 취하고 있다. 즉 Action을 선택하는 Actor Network가 존재하며, Action의 가치를 평가하는 Critic Network가 존재한다는 뜻이다. 그렇기 때문에 최소 Network는 2개 이상이 될 것으로 추측가능하며 여기까지만 본다면 On-policy 알고리즘이라고 생각할 수 있다.
② Deterministic polices to handle Continuous Action Spaces
--> 이 부분인 DDPG 알고리즘의 핵심내용인데, Action Space를 기존의 Discreate 에서 Continuous로 확장했다는 것이다. 실생활에 존재하는 문제들을 해결하기 위해서는 Action space가 매우 커야 하는 데 이를 해결하기 위해 기존의 Policy-gradient 알고리즘이 사용하는 확률적 정책 (stochastic policy)가 아닌 확정적 정책(deterministic policy)을 사용한다.
사실 Policy-gradient 알고리즘 자체가 만들어진 배경을 보면 DQN 과 같은 Value-base 알고리즘의 경우 학습이 완료되면 같은 state가 될 때 q함수가 최대가 되는 action을 선택하는 것으로 고정되어 버린다. 그렇기 때문에 action이 state에 따라 유연하지 않고 고정되어 버리게 되는데 이를 해결하기 위해 policy 자체가 학습되어 지는 Policy gradient 방법이 나온 것이며 여태까지는 확률적 정책을 사용하여 policy를 업데이트 하였다.
하지만 DDPG에서는 μ 라는 state를 입력으로 받으면 action이 결정되서 나오는 deterministic policy를 사용하여 action을 선택한다.
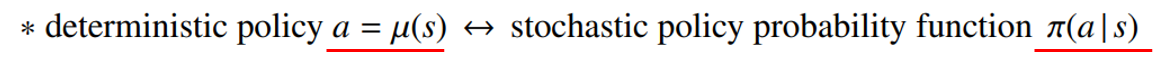
또한 DPG를 사용하면서 얻게 되는 이점이 있는데, 바로 아래와 같이 DPG 방법은 SPG 방법에 비하여 더 적은 sample로도 효율적인 학습이 가능하다는 것이다. SPG의 경우에는 Q함수와 π(a|s)를 구하는 데 state와 action이 둘다 input으로 들어간다. 이에반해 DPG의 경우 state 정보만 있으면 action이 μ함수로 결정이 되기 때문에 input으로 state 정보만 사용이 된다.
상대적으로 2개의 input을 사용하는 것보다 1개의 input을 사용하는 것이 수렴성이 좋을 것이므로 DPG는 상대적으로 적은 에피소드만으로도 효율적인 학습이 가능하다.

③ DQN architecture such as experience replay and target network
--> 앞에서 DDPG는 Off-policy 알고리즘이라고 설명하였다. 그 이유가 바로 DQN에서 사용하는 구조를 동일하게 사용해서 인데, Target Network 를 사용하여 Target policy와 Behavior Policy가 구분되어 진다. 또한 학습 데이터간의 상관관계를 해소하기 위해 replay 메모리를 사용하는데 이는 DQN과 완전히 동일하다고 생각하면 된다.
그러나 DQN과 다른 것이 3가지 정도 있을 것 같은데 살펴보면 다음과 같다.
1) Target Network의 수
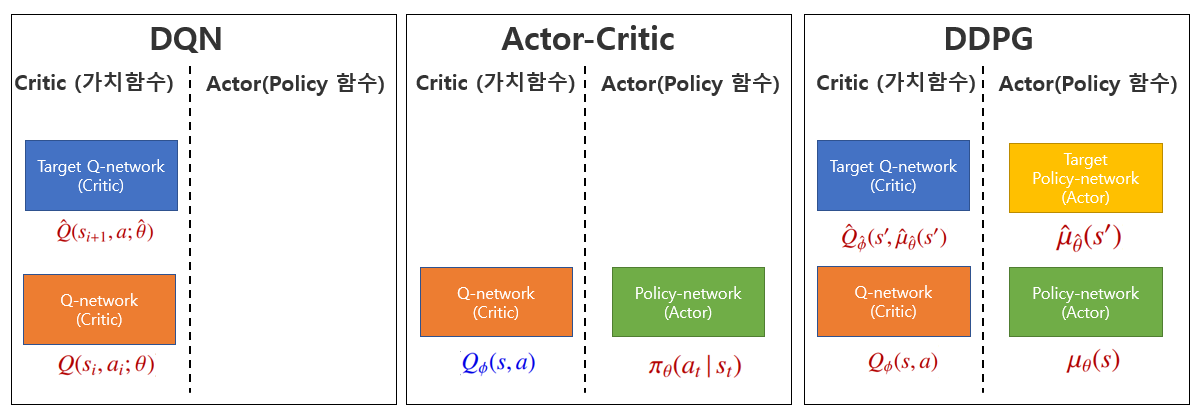
-> 위의 그림이 DDPG 에서 사용하는 인공신경망을 표현한 것으로 앞의 DQN과 Actor-Critic 알고리즘과 비교하면 그 수가 4개로 많은 것을 알 수 있다. 기본적으로 DQN + Actor-Critic을 하게 되면 총 3개가 되어야 할 것 같지만 DDPG에서는 Target Acotor Network가 추가로 필요하다. 그 이유는 DQN의 경우 아래의 식과 같이 Q함수가 최대로 되는 action을 선택
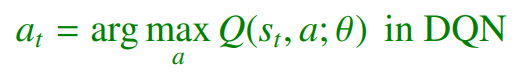
해서 Critic Loss내의 TD Target term을 계산하지만 DDPG의 경우 DPG방법을 사용하므로 action 선택을 위한 함수를 Target actor network로 사용하였다.

2) Weight Update 방법
-> DQN의 경우 C스텝 또는 에피소드 종료 시 마다 Target update를 수행한다. 그러나 DDPG에서는 매스텝 업데이트를 수행하는 대신 일정 비율(tau)만큼 Soft Update를 수행한다.

3) Exploration (탐험) 과 Exploitation(이용)
-> 강화학습에서는 탐험과 이용을 적절히 사용하여 가보지 않은 곳에 대한 경우도 고려할 수 있게 하는데, 이를 위해 ε-greedy 방법을 사용하였다. 처음에는 ε을 크게 설정하여 탐험을 좀더 많이 하는 policy를 선택하다가 에피소드가 많이 진행되면 ε을 낮추어서 탐험을 거의 하지 않고, 학습된 q함수를 통해 action을 선택하는 방법을 사용한다.
Continuos Action Space를 사용하는 DDPG에서도 Exploration을 하기 위해서 Noise를 더해주는 방법을 사용한다. 이산적인 action에서는 아예 다른 action을 선택하지만 연속적인 action에서는 Noise를 약간 더해줘서 값을 살짝 바꿔주는 것이 효과적인 탐험 방법이 될 것 이다.

3) DDPG pseudo-code
-> 앞의 정리 된 내용을 바탕으로 해서 DDPG pseudo-code를 분석해보고 이글을 마치려고 한다.
그전에 pseudo-code를 이해하기 위해 표현된 수식중에 State visitation frequency를 설명하고 분석을 진행하려고 한다.
** State visitation frequency (= 상태방문확률(?) )

State visitation frequency을 해석하면 상태를 방문할 확률 정도로 해석할 수 있는데, 강의에서보면 완전한 확률은 아니고 1-γ 를 곱해주어야 확률이 되지만, 1-γ 는 계산가능한 값이므로 상수항을 곱해도 값에는 크게 변화가 없을 것이므로 상태방문확률로 봐도 무방할 것 같다.
크게 1번과 2번의 식으로 나누어 볼 수 있는 데 처음에는 이해하기 어려워서 아래와 같이 그림으로 표시해 보았다.
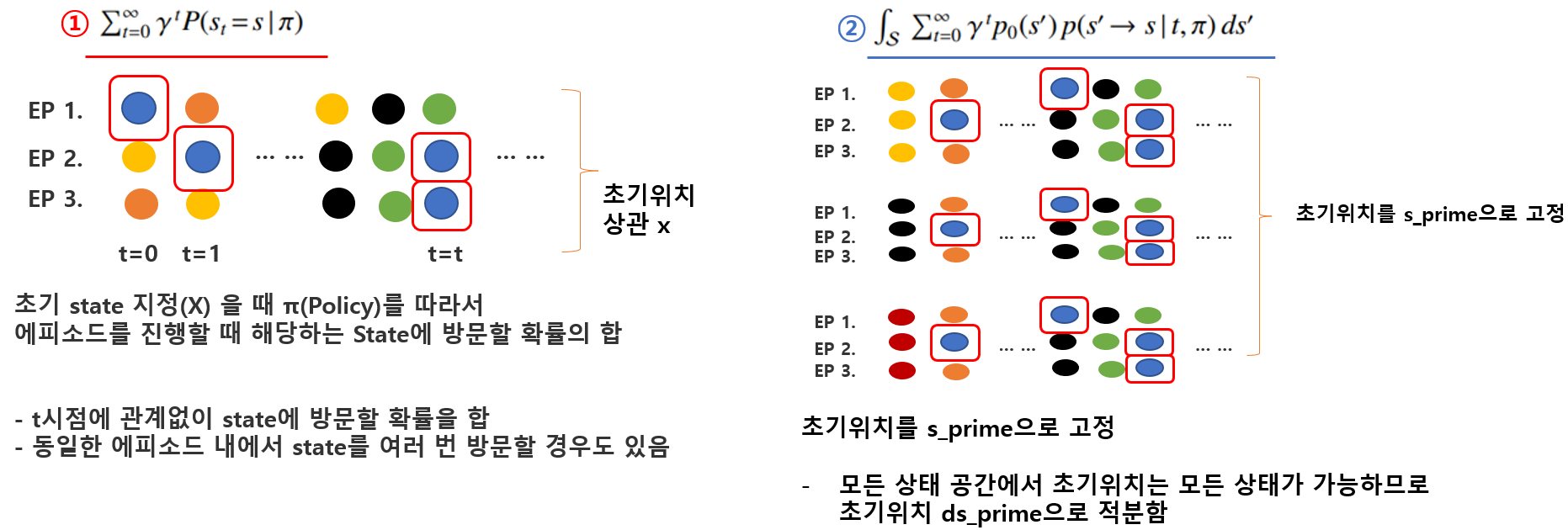
1)번의 경우는 초기위치가 지정되어 있지 않은 상태에서 특정한 state (그림에서는 파란색) 에 방문하는 확률의 합을 나타낸다. 여기서 주의할 점이 특정한 state는 한에피소드 내에서도 여러번 방문할 수 있다는 것이다. t = 2 에 방문했다고 해서 t=5에 방문을 못하는 것이 아니기 떄문에 t에 대해서 0부터 무한대까지 다 더해주어야 한다.
2)번의 경우는 초기위치가 지정되어 있는 것이다. 그림에서보면 특정한 state( 노란색 / 검은색 / 빨간색) 으로 시작 위치가 고정되어 있을 때 특정한 state(그림에서는 파란색)을 방문하는 확률의 합으로 나타낸다. 이 때 초기위치 s_prime은 state 공간내에서 어떤 state 든지 될 수 있으므로 ds_prime으로 적분하여 Continuos State Space에서 확률을 계산하였다.
그렇다면 강의에서 설명한 것처럼 State visitation frequency 가 확률이 아닌데 1-γ을 곱하면 확률로 볼 수 있다는 개념은 무엇일까?

위의 그림에서 3)번의 식을 보면 모든 state에 대해서 합해주는 시그마가 추가되었다. 이 때 시그마를 P확률 앞으로 식을 변경하면, t시점에서 state에 있을 확률을 의미하는데, 이때 state는 모든 존재하는 state에 있을 확률을 더해주어야 되므로 확률이 1이 된다. 즉 위의 그림에서는 특정한 state(파란색공)에 있을 확률이었지만 지금은 초기상태 뿐만아니라 t 시점에서 방문할 수 있는 state가 모든 state로 확장된 것 이다. 이렇게 되면 무한 등비급수를 계산하여 1 / (1-γ)로 계산이 되고, 이를 곱해주면 확률 분포로 생각할 수 있게 된다.

이제 간략하게 위의 DDPG pseudo-code를 분석해 보도록 하자.
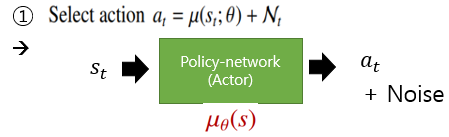
먼저 Actor Network를 통해서 현재 state를 입력받아 Deterministic Policy를 통해 action을 선택한다. 선택된 action에 탐험을위하여 Noise를 추가하고 이것으로 Env 환경과 상호작용을 한다.
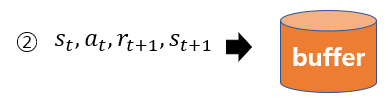
Env에서는 reward 값과 next_state를 보내주며, 이를 리플레이 메모리에 저장한다. 여기서 저장된 리플레이 메모리를 minibatch 만큼 뽑아서 network를 학습하게 된다. 이는 DQN의 방법과 동일하다

세번 째는 Critic Network를 계산하는 방법으로 이때, next_state에 대한 action을 결정하기 위해서 Target Actor network가 사용된다. 이 부분이 DQN과 다른 점이다. 이렇게 선택된 Action과 state로 각각 Critic Network 를 넣어주면 Q함수(액션가치함수)가 나오게 되며, 이를 최소화하는 방향으로 현재의 Critic Network를 업데이트 해주게 된다.
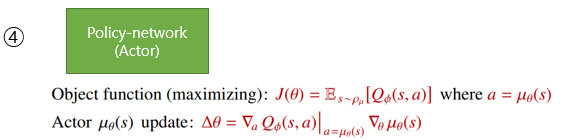
네번 쨰는 Actor Network 업데이트를 진행하는 데, 앞에서 구한 값들을 이용하여 Actor Network를 업데이트 하게 된다.
마지막으로 Actor와 Critic의 Target Network를 업데이트 하면 한 step이 끝나게 되고 이를 모든 스텝과 모든 에피소드 마다 반복하면서 학습이 진행된다.
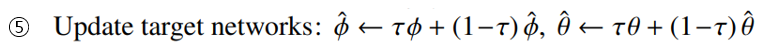
이번에는 DDPG의 이론을 살펴보았다. 글을 자세히 정리하다 보니깐 앞에 공부한 내용도 자연적으로 복습할 수 있는 계기가 되었던 것 같다. 다음에는 DDPG 이론을 참고하여 실제 코드를 구현해보는 실습을 진행하려고 한다.
'머신러닝 딥러닝' 카테고리의 다른 글
| [GAN]1D 그래프 생성하기_BASE (0) | 2023.05.06 |
|---|---|
| [강화학습] DDPG (Deep Deterministic Policy Gradient)실습_ContinuosMountainCar(2/2) (0) | 2023.03.15 |
| [강화학습]A3C_Continuos Actor_Critic_MountainCar (0) | 2023.02.28 |
| [강화학습]A3C_Discrete환경_Cartpole_Mountain_car (2) | 2023.02.24 |
| [강화학습]Continuos A2C(연속적 A2C)_mountain Car (0) | 2023.02.15 |



