
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- FirebaseV9
- expo
- Ros
- 클론코딩
- App
- redux
- TeachagleMachine
- JavaScript
- 정치인
- 딥러닝
- 데이터분석
- Instagrame clone
- selenium
- 카트폴
- 리액트네이티브
- ReactNative
- 사이드프로젝트
- pandas
- React
- 조코딩
- 전국국밥
- coding
- 머신러닝
- python
- 강화학습
- clone coding
- 크롤링
- 강화학습 기초
- 앱개발
- kaggle
- Today
- Total
qcoding
[강화학습]A3C_Discrete환경_Cartpole_Mountain_car 본문
* 이번 실습은 A3C (Asynchronous Advantage Actor-Critic)에 대한 실습내용이다. 실습의 적용은 Cartpole과 Mountain Car에 적용하였으며, 결론적으로 Cartpole의 환경에서만 문제를 해결하였다. 현재까지 실습을 진행한 알고리즘을 정리하면
- > value_based (dqn)
-> Policy_based (Reinforce / TD1step - A2C / TD1step - Continuos A2C )
이며, Mountain Car 환경이 성공한 것은 off-policy value_based인 dqn 알고리즘이다. Mountain car와 같이 즉각적인 보상이 아닌 goal에 도착했을 때 큰 보상을 얻는 환경의 경우 on-policy알고리즘으로 action을 강화하는 policy_based 알고리즘으로는 해결이 어려웠다.
이번에 실습할 A3C의 경우 on-policy 알고리즘에서 학습데이터간의 상관관계의 문제를 깨기 위해, dqn에서 했던 리플레이 메모리 대신 Multi-Thread를 통한 병렬 처리와 Global Network를 Asynchrous(비동기적)으로 학습하는 방법을 통해 dqn과 a2c의 장점을 합친 방법이다.

A3C가 나온 Asynchronous Methods for Deep Reinforcement Learning (https://arxiv.org/abs/1602.01783)
에서는 4가지 알고리즘 방식에 적용하였을 때 모두 좋은 결과를 얻었으며 대표적으로 A2C에 적용하여, 이 알고리즘을 A3C라고 지칭한다고 한다.
논문에서 나온 4가지 알고리즘은 다음과 같다.
이 중 A2C에 대한 실습을 진행하며, 환경으로 Discrete(이산적)인 Action space를 갖는 Cartpole과 MountainCar에서 진행하였다. 아래와 같은 순서로 진행한다.
(* 아래의 책을 구매하고 공부하면서 작성하였으며, 책에 나온 코드를 수정 및 변경하여 사용하였습니다.)
https://wikibook.co.kr/reinforcement-learning/
파이썬과 케라스로 배우는 강화학습: 내 손으로 직접 구현하는 게임 인공지능
“강화학습을 쉽게 이해하고 코드로 구현하기” 강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지
wikibook.co.kr
1) 알고리즘 소개
2) 코드
3) 실습 결과
1) 알고리즘 소개

위의 그림은 일반적인 A2C를 나타낸 그림으로 Critic에서 TD One-Step 또는 N-step을 적용할 수 있으며 이전에 진행하였던 A2C에서는 One-step을 적용하고 이번에 진행하는 A3C에서는 N-step을 적용하였다. Actor 부분은 A2C와 동일하며 이번실습에서 추가된 것이 있다면 엔트로피가 추가 된 것 이다.

엔트로피를 그냥 추가한 것은 아니고 (-)를 (+)로 변경한 뒤 Total Loss 구하는 부분에 추가하였다. 그 이유를 보면 Total Loss를 감소시키도록 학습이 진행될 텐데 아래의 log(x) 그래프에서 보면 x축 즉 p_i (확률)값이 0~1 사이를 움직인다고 할때 Loss가 작아지는 방향은 균등한 분포가 되게 하는 방향으로, A3C에서 다양한 병렬처리 환경을 만들 때, 여러환경이 다양한 Action을 수행하기 위한 일종의 규제와 같은 개념으로 엔트로피를 사용하였다.

학습의 전체적인 개략도를 보면 아래와 같다.


위의 내용을 기반으로 전체적인 학습 내용을 설명하면
1) 오류함수로 Total Loss 구하기
2) Local 신경망의 Gradient 계산하기 - 안정적 학습을 위해 gradient clipping
3) Local 신경망의 오류함수를 줄이는 방향으로 Global 신경망 업데이트
4) Local 신경망의 가중치를 글로벌 신경망의 가중치로 업데이트
5) 쌓여있던 sample 삭제 후 1) ~ 4)의 과정을 반복함.
여기서 가장 중요한 것이 3) Local 신경망의 오류함수를 줄이는 방향으로 글로벌 신경망을 업데이트 하는 것이다. 아래와 같이 Local의 Total Loss는 Θ_local 에 의한 gradient vector를 갖는데,

이를 업데이트할 때에는 global parameter를 업데이트하게 된다. 즉 여러개의 local 신경망의 각각의 loss를 줄이는 방향으로 Global 신경망을 업데이트 하므로 다양한 환경에 맞는 parameter를 학습할 수 있는 것이다.

업데이트 된 global 신경망은 다시 Local 신경망으로 가중치가 4)번에서 업데이트 되며 이 과정이 반복된다.
2) 코드
--> 코드의 경우 공통되는 부분은 Carpole 코드로 나타냈으며 Mountain Car환경에서 변경되는 부분만 Mountain Car에 작성하였습니다.
2-1) CartPole 코드
### 패키지 설치
!sudo apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb \
xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
!pip install pyvirtualdisplay
!pip install piglet
## gym
!pip install gym[classic_control]
##ffmpeg
!sudo apt-get install ffmpeg -y### 라이브러리 import
### import
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1400, 900))
display.start()
from base64 import b64encode
from glob import glob
from IPython.display import HTML
from IPython import display as ipy_display
from gym import logger as gym_logger
from gym.wrappers.record_video import RecordVideo
import tensorflow as tf
from tensorflow import keras
from keras.utils.vis_utils import plot_model
from tensorflow_probability import distributions as tfd
import sys
import time
import threading
import numpy as np
import random
import gym
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import os
import warnings
warnings.filterwarnings(action='ignore')### colab에서 video 실행을 위한 함수
#### show video func
def show_video(runner_idx=None,test_mode = False, mode='train', filename=None):
mp4_list = glob(mode+'/*.mp4') if test_mode else glob(mode + f'/{runner_idx}/*.mp4')
# print('mp4_list' , mp4_list)
if mp4_list:
if filename :
file_lists = glob(mode+'/'+filename) if test_mode else glob(mode+f'/{runner_idx}/'+filename)
if not file_lists:
# print('mp4_list exist')
print('No {} found'.format(filename))
return -1
mp4 = file_lists[0]
else:
mp4 = sorted(mp4_list)[-1]
print(mp4)
video = open(mp4, 'r+b').read()
encoded = b64encode(video)
ipy_display.display(HTML(data='''
''' % (encoded.decode('ascii'))))
else:
print('No video found')
return -1### Global Network
# 멀티쓰레딩을 위한 글로벌 변수
global episode, score_avg, score_max, success_total , max_pos_max, done
episode, score_avg, score_max, success_total , done = 0, 0, 0, 0, False
num_episode = 10000# 브레이크아웃에서의 A3CAgent 클래스 (글로벌신경망)
class A3CAgent():
def __init__(self):
self.env_name = 'CartPole-v1'
self.env = gym.make(self.env_name)
# 상태와 행동의 크기 정의
self.state_size = self.env.observation_space.shape[0]
self.action_size = self.env.action_space.n
# A3C 하이퍼파라미터
self.discount_factor = 0.999
self.learning_rate = 0.001
# 쓰레드의 갯수
self.threads = 16
# 글로벌 인공신경망 생성
self.global_model = self.actor_critic_dnn()
# 글로벌 인공신경망의 가중치 초기화
# self.global_model.build(tf.TensorShape((None, *self.state_size)))
# 최적화 알고리즘 설정, 미분값이 너무 커지는 현상을 막기 위해 clipnorm 설정
self.optimizer = keras.optimizers.Adam(learning_rate = self.learning_rate, clipnorm=5.0)
# 텐서보드 설정
self.writer = tf.summary.create_file_writer('summary/a3c/cartpole')
# 학습된 글로벌신경망 모델을 저장할 경로 설정
self.model_path = os.path.join(os.getcwd(), 'save_model', 'model','a3c')
# Global Dnn
# Dnn 모델 생성
def actor_critic_dnn(self):
### state가 들어감
input_ = keras.layers.Input(shape=(self.state_size))
### Actor (정책평가)
actor_fc = keras.layers.Dense(64, activation='tanh')(input_)
actor_fc = keras.layers.Dense(32, activation='tanh')(actor_fc)
policy = keras.layers.Dense(self.action_size, activation='softmax', kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(actor_fc)
## Critic (가치평가)
critic_fc1 = keras.layers.Dense(128, activation='tanh')(input_)
critic_fc2 = keras.layers.Dense(64, activation='tanh')(critic_fc1)
critic_fc3 = keras.layers.Dense(24, activation='tanh')(critic_fc2)
value = keras.layers.Dense(1, kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(critic_fc3)
## model
model = keras.models.Model(inputs=[input_], outputs=[policy, value])
return model
# 쓰레드를 만들어 학습을 하는 함수 --> main에 해당함.
def train(self):
# 쓰레드 수 만큼 Runner 클래스 생성
runners = [Runner(self.action_size, self.state_size,
self.global_model, self.optimizer,
self.discount_factor, self.env_name,
self.writer, idx) for idx in range(self.threads)]
# 각 쓰레드 시정
for i, runner in enumerate(runners):
print("Start worker #{:d}".format(i))
runner.start()
# runner.join() ### thread 종료 후 main이 끝날 수 있ㅔ함
# 10분 (600초)에 한 번씩 모델을 저장
#### 여기 while 부분 때문에 종료가 안됐었음
#### time.sleep() 마다 동작하므로 그 전에는 동작하지 않음
while True:
global episode, done
cond_episode= episode % 100 == 0 or episode % num_episode == 0
if cond_episode and episode != 0 and done: ### 에피소드 단위로 weights 저장하기
print(f"{episode}th global model saved!")
self.global_model.save_weights(f"save_model/cartpole/{episode}th/", save_format="tf")
if episode > num_episode: ### 학습이 다 되면 반복문을 끝내기 위해서 추가함
print("episode exit")
# sys.exit()
break
# self.global_model.save_weights(self.model_path, save_format="tf") ### 시간 단위로 weights 저장하기
# time.sleep(60 * 1)
# print("global model saved!")### Local Network
# 액터러너 클래스 (쓰레드)
class Runner(threading.Thread):
def __init__(self, action_size, state_size, global_model,
optimizer, discount_factor, env_name, writer, idx):
threading.Thread.__init__(self)
# A3CAgent 클래스에서 넘겨준 하이준 파라미터 설정
self.action_size = action_size
self.state_size = state_size
self.global_model = global_model
self.optimizer = optimizer
self.discount_factor = discount_factor
self.states, self.actions, self.rewards = [], [], []
# 환경, 로컬신경망, 텐서보드 생성
self.local_model = self.actor_critic_dnn()
## 환경 생성 - 비디오 레코딩
self.env = gym.make(env_name)
self.env = RecordVideo(self.env, f'./train/{idx}', episode_trigger =lambda episode_number: True )
self.env.metadata = {'render.modes': ['human', 'ansi']}
self.writer = writer
# 학습 정보를 기록할 변수
self.avg_p_max = 0 ## 평균
self.avg_loss = 0
# k-타임스텝 값 설정
self.t_max = 10 #### 이값으로 n-step값을 정할 수 있음
self.t = 0
# Local Dnn
def actor_critic_dnn(self):
### state가 들어감
input_ = keras.layers.Input(shape=(self.state_size))
### Actor (정책평가)
actor_fc = keras.layers.Dense(64, activation='tanh')(input_)
actor_fc = keras.layers.Dense(32, activation='tanh')(actor_fc)
policy = keras.layers.Dense(self.action_size, activation='softmax', kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(actor_fc)
## Critic (가치평가)
critic_fc1 = keras.layers.Dense(128, activation='tanh')(input_)
critic_fc2 = keras.layers.Dense(64, activation='tanh')(critic_fc1)
critic_fc3 = keras.layers.Dense(24, activation='tanh')(critic_fc2)
value = keras.layers.Dense(1, kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(critic_fc3)
## model
model = keras.models.Model(inputs=[input_], outputs=[policy, value])
return model
# 텐서보드에 학습 정보를 기록
def draw_tensorboard(self, score, step, e):
avg_p_max = self.avg_p_max / float(step)
with self.writer.as_default():
tf.summary.scalar('Total Reward/Episode', score, step=e) ## score = reward의 합
tf.summary.scalar('Average Max Prob/Episode', avg_p_max, step=e) ## avg_p_max는 policy중 가장 큰 action의 확률
tf.summary.scalar('Duration/Episode', step, step=e)
# 정책신경망으로 행동 선택
def get_action(self, state):
## policy 선택
policy , value = self.local_model(state)
policy = np.array(policy[0])
action = np.random.choice(self.action_size, 1, p=policy)[0]
# print(f'action : {action} , policy:{policy}')
return action, policy
# 샘플을 저장
def append_sample(self, state, action, reward):
self.states.append(state)
one_hot_action = tf.one_hot([action], self.action_size) ## continuos action 이므로 여기서는 one_hot 필요없음
# act = np.zeros(self.action_size) ## one hot encoding one-hot이 필요한 이유는 one-hot_action x policy_prob 실제했던 action_prob를 구하기 위함
# act[action] = 1
self.actions.append(one_hot_action)
self.rewards.append(reward)
# k-타임스텝의 prediction 계산
def discounted_prediction(self, rewards, done):
discounted_prediction = np.zeros_like(rewards)
running_add = 0
if not done:
# value function
last_state = np.float32(np.expand_dims(self.states[-1], axis=0))
running_add = self.local_model(last_state)[-1][0].numpy()
for t in reversed(range(0, len(discounted_prediction))):
running_add = running_add * self.discount_factor + rewards[t]
discounted_prediction[t] = running_add
return discounted_prediction
# 저장된 샘플들로 A3C의 오류함수를 계산
def compute_loss(self,done):
discounted_prediction = self.discounted_prediction(self.rewards,done)
discounted_prediction = np.array(discounted_prediction).reshape(len(discounted_prediction),-1) ### (999,) => (999,1) 로 2차원으로 변경
# discounted_prediction = tf.convert_to_tensor(discounted_prediction[:, None],dtype=tf.float32)
### policy_prob 와 action_prob가 필요함 --> states가 여러개 이므로 각각이 여러개가 나옴
policies_prob, values = self.local_model(np.array(self.states))
# 가치 신경망 업데이트 --> value 함수 값이 필요함
advantages = discounted_prediction - values
critic_loss = 0.5 * tf.reduce_sum(tf.square(advantages)) ### scalar 값
# 정책 신경망 업데이트 --> action_prob가 필요함
actions = tf.convert_to_tensor(self.actions, dtype=tf.float32) ## one-hot action값이 존재함
action_prob = tf.reduce_sum(actions * policies_prob, axis=1, keepdims=True) ## 실제 수행했던 action_prob를 계산함
cross_entropy = - tf.math.log(action_prob + 1e-10)
actor_loss = tf.reduce_sum(cross_entropy * tf.stop_gradient(advantages)) ## scalar 값
entropy = tf.reduce_sum(np.array(policies_prob) * tf.math.log(np.array(policies_prob) + 1e-10), axis=1)
entropy = tf.reduce_sum(entropy)
actor_loss += 0.01 * entropy
total_loss = 0.5 * critic_loss + actor_loss ## critic_loss + actor_loss + entropy
return total_loss
# 로컬신경망을 통해 그레이디언트를 계산하고, 글로벌 신경망을 계산된 그레이디언트로 업데이트
def train_model(self,done):
global_params = self.global_model.trainable_variables
local_params = self.local_model.trainable_variables
with tf.GradientTape() as tape:
total_loss = self.compute_loss(done)
# 로컬신경망의 그레이디언트 계산
grads = tape.gradient(total_loss, local_params, unconnected_gradients=tf.UnconnectedGradients.ZERO) ### gradient가 None 일 때 WARNING:tensorflow:Gradients do not exist for variables 에러발생
# 안정적인 학습을 위한 그레이디언트 클리핑
grads, _ = tf.clip_by_global_norm(grads, 40.0)
# 로컬신경망의 오류함수를 줄이는 방향으로 글로벌신경망을 업데이트
self.optimizer.apply_gradients(zip(grads, global_params))
# 로컬신경망의 가중치를 글로벌신경망의 가중치로 업데이트
self.local_model.set_weights(self.global_model.get_weights())
# 업데이트 후 저장된 샘플 초기화
self.states, self.actions, self.rewards = [], [], []
def run(self):
# 액터러너끼리 공유해야하는 글로벌 변수
global episode, score_avg, score_max, success_total , done
while episode < num_episode:
done = False
step = 0
score = 0
state = self.env.reset()
# # 랜덤으로 뽑힌 값 만큼의 프레임동안 움직이지 않음
# for _ in range(random.randint(1, 30)):
# observe, _, _, _ = self.env.step(1)
while not done:
step += 1
self.t += 1
# 정책 확률에 따라 행동을 선택
action, policy = self.get_action(np.expand_dims(state, axis=0))
# 선택한 행동으로 환경에서 한 타임스텝 진행
next_state, reward, done, info = self.env.step(action)
# 정책확률의 최대값
self.avg_p_max += np.amax(policy)
score += reward
### 보상설계
# def get_reward(pos, angle , done):
# ### 위치 / 속도 조건으로 보상크게
# cond_pos = (pos < 2.0) and (pos > -2.0)
# cond_angle = (angle < 5.0) and (angle > -5.0)
# ### 상점
# if cond_pos or cond_angle:
# return 1.0
# elif cond_pos:
# return 0.5
# elif cond_angle:
# return 0.5
# ### 벌점
# elif done:
# return -5.0
# elif (pos > 2.5) or (pos < -2.5):
# return -0.5
# elif (angle > 10.0) or (angle < -10.0):
# return -1.0
# ### position
# pos = next_state[0]
# ### velocity
# angle = next_state[2]
# reward = get_reward(pos, angle, done) ## agent가 받는 보상설계
reward = 0.1 if not done or score == 500 else -1 ## agent가 받는 보상설계
## 샘플을 저장 --> A2C의 경우 On-policy 이므로 state 를 사용 - TD_n step 일 때 (next_state는 사용하지 x )
## Reinforce 알고리즘의 G_t (리턴값) 계산하는 것과 동일한 원리
## reward + discount_factor * running_add 로 (n)스텝의 상태가치 (v)를 계산함
self.append_sample(state, action, reward)
# 다음 상태를 현재 상태로 정의
state = next_state
# 에피소드가 끝나거나 최대 타임스텝 수에 도달하면 학습을 진행
# 에피소드가 끝나거나 최대 타임스텝 수에 도달하면 학습을 진행
if self.t >= self.t_max or done:
self.train_model(done)
self.t = 0
if done:
# 각 에피소드 당 학습 정보를 기록
episode += 1 ## 기존
score_max = score if score > score_max else score_max ## 기존
score_avg = 0.9 * score_avg + 0.1 * score if score_avg != 0 else score ## 기존
log = "episode: {:5d} | score : {:4.1f} | ".format(episode, score)
log += "success_total : {} | ".format(success_total)
log += "score max : {:4.1f} | ".format(score_max)
log += " score avg : {:.3f}".format(score_avg)
print(log)
self.draw_tensorboard(score, step, episode)
self.avg_p_max = 0
step = 0### 학습시작 Main
##### 학습 시작 #########
global_agent = A3CAgent()
global_agent.daemon = True ## main 이 종료되면 하위의 thread가 다 종료됨
global_agent.train()### Tensorboard
%load_ext tensorboard
%tensorboard --logdir='./summary/a3c/cartpole'### 학습된 Runner 영상확인
## runner index
runner_idx = '13'
file_list=os.path.join(os.getcwd(),f'train/{runner_idx}')
dir_list=os.listdir(file_list)
idex_list= []
for list_ in dir_list:
if "mp4" in list_:
idx=list_.split('.')[0].split('-')[-1]
idex_list.append(int(idx))
episode = np.max(idex_list)
# print(f'episode_list : {idex_list}')
print(f"episode : {episode}" )
filename = f'rl-video-episode-{episode}.mp4'
show_video(runner_idx=runner_idx,filename=filename)### 저장된 Weights로 Global Network를 평가하기
class Test_ActorCritic():
def __init__(self, state_size, action_size):
## 상태 및 행동 size 정의
## stae = 2가지 정보 , action = 3가지 정보
self.state_size = state_size
self.action_size = action_size
# ContinuosActorCritic 신경망 모델 생성
self.model = self.actor_critic_dnn()
# 정책신경망으로 행동 선택
def get_action(self, state):
## policy 선택
policy , value = self.model(state)
policy = np.array(policy[0])
action = np.random.choice(self.action_size, 1, p=policy)[0]
# print(f'action : {action} , policy:{policy}')
return action, policy
# Dnn
def actor_critic_dnn(self):
### state가 들어감
input_ = keras.layers.Input(shape=(self.state_size))
### Actor (정책평가)
actor_fc = keras.layers.Dense(64, activation='tanh')(input_)
actor_fc = keras.layers.Dense(32, activation='tanh')(actor_fc)
policy = keras.layers.Dense(self.action_size, activation='softmax', kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(actor_fc)
## Critic (가치평가)
critic_fc1 = keras.layers.Dense(128, activation='tanh')(input_)
critic_fc2 = keras.layers.Dense(64, activation='tanh')(critic_fc1)
critic_fc3 = keras.layers.Dense(24, activation='tanh')(critic_fc2)
value = keras.layers.Dense(1, kernel_initializer=keras.initializers.RandomUniform(-1e-3, 1e-3))(critic_fc3)
## model
model = keras.models.Model(inputs=[input_], outputs=[policy, value])
return model#### 학습 환경
ENV_NAME = 'CartPole-v1'
env = gym.make(ENV_NAME)
# 비디오 레코딩
env = RecordVideo(env, './test', episode_trigger = lambda episode_number: True)
env.metadata = {'render.modes': ['human', 'ansi']}
# CartPole 환경의 상태와 행동 크기 정의
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
#### Test 모델 생성 weights load
test_global_agent = Test_ActorCritic(state_size, action_size)
load_model=True
if load_model:
# 위에서 정의한 DQN 클래스를 활용하여 agent 정의
load_model = '9900th'
test_global_agent.model.load_weights(f'save_model/cartpole/{load_model}/')
print(f"{load_model} model load !!!")
score = 0
state = env.reset()
done = False
max_position = -0.4
### 모델 평가
while not done:
# 현재 상태에 대하여 행동 정의
action , policy = test_global_agent.get_action(state[np.newaxis,:])
# env.step 함수를 이용하여 행동에 대한 다음 상태, 보상, done flag 등 획득
next_state, reward, done, info = env.step(action)
car_pos = next_state[0]
if car_pos > max_position:
max_position = car_pos
# 해당 에피소드의 최종 score를 위해 reward 값 누적
score += reward
# 다음 상태를 현재 상태로 정의
state = next_state
print(f'Score : {score : .3f}')### Test 비디오 확인
### video
show_video(test_mode=True,mode='test')
2-1) Mountain Car코드
### Local Network에서 Tensorboard 함수
# 텐서보드에 학습 정보를 기록
def draw_tensorboard(self, score, step, e, max_pos_max):
avg_p_max = self.avg_p_max / float(step)
with self.writer.as_default():
tf.summary.scalar('Total Reward/Episode', score, step=e) ## score = reward의 합
tf.summary.scalar('Average Max Prob/Episode', avg_p_max, step=e) ## avg_p_max는 policy중 가장 큰 action의 확률
tf.summary.scalar('Duration/Episode', step, step=e)
tf.summary.scalar('max_pos_max', max_pos_max, step=e) ## 에피소드마다 max_pos를 기록함
### Local Network에서 Run함수
def run(self):
# 액터러너끼리 공유해야하는 글로벌 변수
global episode, score_avg, score_max, success_total , max_pos_max, done
while episode < num_episode:
done = False
step = 0
score = 0
state = self.env.reset()
# # 랜덤으로 뽑힌 값 만큼의 프레임동안 움직이지 않음
# for _ in range(random.randint(1, 30)):
# observe, _, _, _ = self.env.step(1)
while not done:
step += 1
# 정책 확률에 따라 행동을 선택
action, policy = self.get_action(np.expand_dims(state, axis=0))
# 선택한 행동으로 환경에서 한 타임스텝 진행
next_state, reward, done, info = self.env.step(action)
# 정책확률의 최대값
self.avg_p_max += np.amax(policy)
score += reward
### 보상설계
### position에 따라서 action이 맞으면 reward를 줌
car_pos = next_state[0]
car_vel = next_state[1]
if car_vel > 0:
reward = float(((car_pos+0.5)*20)**2/10+15*car_vel - step/300)
else:
reward = float(((car_pos+0.5)*20)**2/10 - step/300)
### max position
if car_pos > max_pos_max:
max_position = car_pos
else:
max_position= max_pos_max
# ## 성공 시 success
if car_pos >= 0.5:
reward+=100
success_total +=1 ### 추가
## 샘플을 저장 --> A2C의 경우 On-policy 이므로 state 를 사용 - TD_n step 일 때 (next_state는 사용하지 x )
## Reinforce 알고리즘의 G_t (리턴값) 계산하는 것과 동일한 원리
## reward + discount_factor * running_add 로 (n)스텝의 상태가치 (v)를 계산함
self.append_sample(state, action, reward)
# 다음 상태를 현재 상태로 정의
state = next_state
# 에피소드가 끝나거나 최대 타임스텝 수에 도달하면 학습을 진행
# self.t >= self.t_max or
if done:
## runner 각각 학습
self.train_model()
# 각 에피소드 당 학습 정보를 기록
episode += 1 ## 기존
score_max = score if score > score_max else score_max ## 기존
score_avg = 0.9 * score_avg + 0.1 * score if score_avg != 0 else score ## 기존
max_pos_max = max_position if max_position > max_pos_max else max_pos_max ## 추가
log = "episode: {:5d} | score : {:4.1f} | ".format(episode, score)
log += "success_total : {} | ".format(success_total)
log += "score max : {:4.1f} | ".format(score_max)
log += f"max_pos_max : {max_pos_max : .3f} |"
log += " score avg : {:.3f}".format(score_avg)
print(log)
self.draw_tensorboard(score, step, episode, max_pos_max)
self.avg_p_max = 0
step = 0위의 코드에서 reawrd와 tensorboard 부분은 다르고 env_name = MountainCar-v0 가 달라진 것만 제외하면 거의 동일하다.
3) 실습결과
3-1) Cartpole

-> A3C의 경우 실습해보면 학습이 매우 빠른 것을 알 수 있는데, 그대신 다양한 환경에서 경험을 하다보니 에피소드가 매우 많이 필요하다. 10,000회 정도를 수행하였을 때, Score는 약 115.7로 부족한 성능을 보였는데, 학습이 잘진행되고 있는 것으로 봐서는 에피소드를 늘리면 더 잘 될 것으로 생각된다.

위의 Max Prob는 정책신경망에서 가장큰 action을 할 확률인데, Policy gradient가 reward가 큰 action을 강화하는 것을 볼 때 Max Prob가 증가하게 되면 특정한 Action이 강화되고 있는 것으로 학습의 진행정도를 확인할 수 있다.

위의 Total Reward는 Cartpole 환경에서 받는 reward로 max는 500까지 있으며 대략 평균적으로 200이 넘어야 문제를 해결한 것으로 보는데, 10,000번의 에피소드로는 부족하여 좀더 많은 학습을 진행하면 무난하게 문제가 해결될 것이라고 생각된다. 결론적으로 A3C를 통해 Cartpole 문제는 해결 가능하다.
3-2) Mountain Car

-> Mountain car의 문제의 경우 on-policy 로는 해결이 불가능하다는 것을 알고있엇기에 이번에는 에피소드를 20,000로 Cartpole문제 보다 더 많은 에피소드를 수행하였다. 그러나 결과적으로 성공은 단한번도 하지 못하였으며 max_pos도 goal (0.5)에 비하여 낮은 값을 갖는 것을 볼 수 있다.

Max Prob을 보면 이미 1로 수렴하여, state에 대해 action이 거의 확정적으로 정해진 것을 볼 수 있다. 가장 좋은 action을 학습하였음에도 불구하고 문제는 해결되지 않았다.
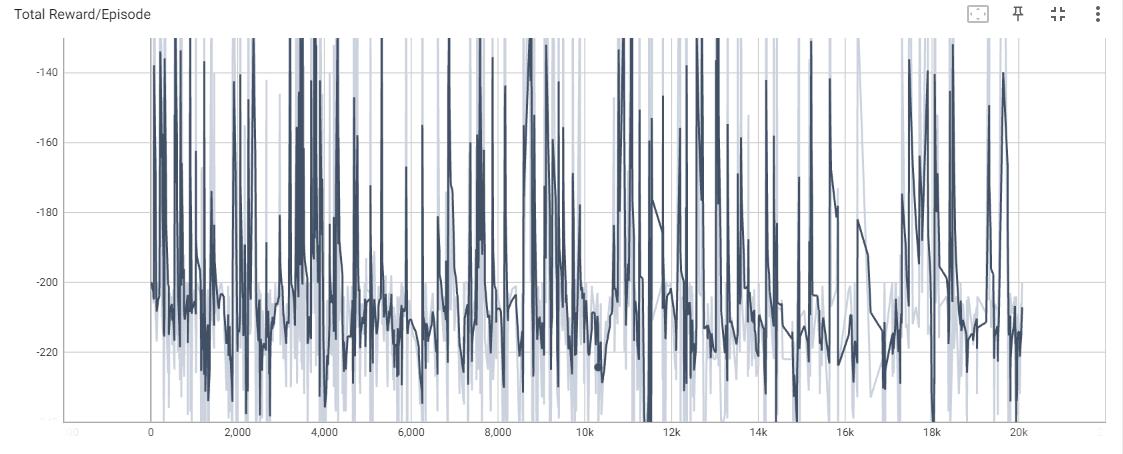
Total Reward도 변동성이 있기는 하지만 개선되는 방향은 아닌 것으로 보이며, 잘 진행되지 않는다.
결론적으로 A3C도 Mountain Car는 해결이 되지 못하였다.
* 다음 실습으로는 DDPG / PPO 등과 같은 다양한 알고리즘을 공부하고 문제에 적용시켜볼 계획이다.
(*Mountain Car의 경우 n-step 대신 에피소드 done 일 경우에만 학습을 진행하였음)
'머신러닝 딥러닝' 카테고리의 다른 글
| [강화학습] DDPG (Deep Deterministic Policy Gradient) 강화학습 (1/2)_이론 (1) | 2023.03.11 |
|---|---|
| [강화학습]A3C_Continuos Actor_Critic_MountainCar (0) | 2023.02.28 |
| [강화학습]Continuos A2C(연속적 A2C)_mountain Car (0) | 2023.02.15 |
| [강화학습]A2C (Actor-Critic)CartPole_Mountain Car 문제 (0) | 2023.02.11 |
| [강화학습]정책기반 강화학습_Policy Gradient_Reinforce_Cartpole (0) | 2023.02.05 |



