
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- python
- App
- pandas
- redux
- clone coding
- 머신러닝
- GYM
- 클론코딩
- TeachagleMachine
- FirebaseV9
- Instagrame clone
- 카트폴
- 조코딩
- 강화학습
- Ros
- 사이드프로젝트
- 딥러닝
- 리액트네이티브
- JavaScript
- 전국국밥
- coding
- 데이터분석
- React
- kaggle
- Reinforcement Learning
- expo
- 강화학습 기초
- selenium
- 앱개발
- ReactNative
- Today
- Total
qcoding
[데이터분석실습][회귀_RF/RIDGE/LASSO]자전거 수요예측 본문
## kaggle 대회 자료를 통해 실습진행
https://www.kaggle.com/competitions/bike-sharing-demand/data
Bike Sharing Demand | Kaggle
www.kaggle.com
1) 데이터 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
# 데이터 불러오기
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
submission=pd.read_csv('./sampleSubmission.csv')
# 데이터확인
train.head()
# 데이터 파악하기
train.info()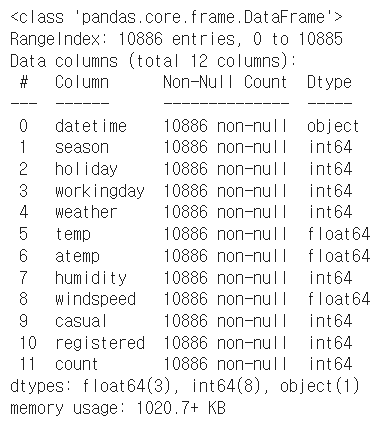
2) 시각화를 위함 피처 엔지니어링
2-1) datatime 변환 ( object 에서 year / month 등 정보 추출하기) -> datetime 형태로 안바꿈!
# 데이터 타입 변경
# 날짜 생성 피처 ex) 2011-01-01
train['date']=train['datetime'].apply(lambda x:x.split()[0])
# 연도 / 월 / 일 / 시 /분 /초 로 분리
train['year']=train['datetime'].apply(lambda x:x.split()[0].split("-")[0])
train['month']=train['datetime'].apply(lambda x:x.split()[0].split("-")[1])
train['day']=train['datetime'].apply(lambda x:x.split()[0].split("-")[2])
train['hour']=train['datetime'].apply(lambda x:x.split()[1].split(":")[0])
train['minute']=train['datetime'].apply(lambda x:x.split()[1].split(":")[1])
train['second']=train['datetime'].apply(lambda x:x.split()[1].split(":")[2])
train.head()

2-2) 요일 피처를 생성함 -> calendar와 datetime 이용
## 요일 변경 예시
from datetime import datetime
import calendar
# 날짜 -> 요일 변환 예시
date=train['date'][100]
# datetime으로 변경 -> 요일로변경 (숫자)
date_weekday_number=datetime.strptime(date,'%Y-%m-%d').weekday()
# 숫자로 변경된 요일을 실제 문자료 변경함
calendar.day_name[date_weekday_number]
# 요일 피처 추가함
# 요일 피처추가
train['weekday']=train['date'].apply(
lambda dataString:
calendar.day_name[datetime.strptime(dataString,'%Y-%m-%d').weekday()]
)
train
2-3) season과 weather 시각화를 위해 숫자형 --> 범주형으로 변경함
# weather / season 데이터처리
# 시각화를 위해서 기존 숫자형 --> 범주형으로 변경함
train['season'] = train['season'].map({
1:'Spring',
2:'Summer',
3:'Fall',
4:'Winter'
})
train['weather']=train['weather'].map({
1:'Clear',
2:'Mist,Few clouds',
3:'Light Snow, Rain, Thunderstorm',
4:'Heavy Rain, Thunderstorm, Snow,Fog'
})
train.head(5)
3) 데이터 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
# 주피터 노트북에서 바로출력을 위해서 사용함
%matplotlib inline3-1) 분포도
-> Target 데이터인 count의 분포를 확인함 (회귀 문제에서는 모델이 좋은 성능을 내려면 정규분포를 따라야 함)
# 분포도 - 수치형 데이터의 집계를 나타냄 (개수 , 비율)
mpl.rc('font',size=15)
sns.displot(data=train['count']);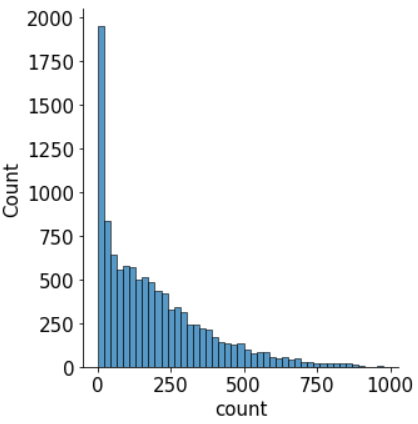
-> 그래프상에서 보면 count 값이 0으로 치우쳐져 있으므로 정규분포를 따르지 않음
-> 정규 분포에 가깝게 만들기 위해 사용하는 방법으로 로그변환을 사용함
# target 값에 로그변환사용함
sns.displot(data=np.log(train['count']))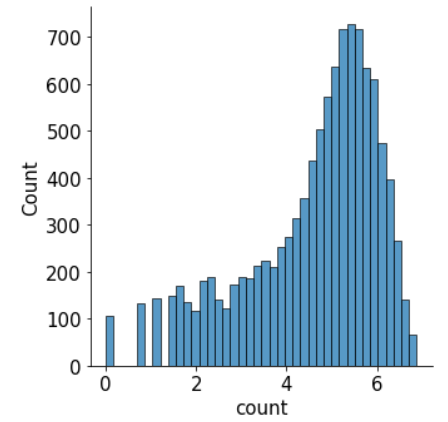
-> 로그변환을 통해 정규분포에 가까워 진것을 확인함
-> 피처를 활용해 count를 예측하는 것보다 log(count) 를 예측하는 편이 더 정확함
-> 후처리로 log 변환된 값을 지수변환 처리 해주어야함
3-2) 막대그래프
# m행 n형 Figure 준비하기
# m 행 n형 Figure 준비하기
mpl.rc('font',size=14)
mpl.rc('axes',titlesize=15)
figure,axes = plt.subplots(nrows=3 , ncols=2)
# 그리드 사이에 여백확보
plt.tight_layout()
# 전체 Figure 사이즈 설정
figure.set_size_inches(10,9)
# 각 axes에 그래프 할당 및 title / 세부 설정
# 각 axes에 그래프 할당
sns.barplot(x='year' ,y='count', data=train , ax=axes[0,0])
sns.barplot(x='month' ,y='count', data=train , ax=axes[0,1])
sns.barplot(x='day' ,y='count', data=train , ax=axes[1,0])
sns.barplot(x='hour' ,y='count', data=train , ax=axes[1,1])
sns.barplot(x='minute' ,y='count', data=train , ax=axes[2,0])
sns.barplot(x='second' ,y='count', data=train , ax=axes[2,1])
axes[0,0].set(title='year')
axes[0,1].set(title='month')
axes[1,0].set(title='day')
axes[1,1].set(title='hour')
axes[2,0].set(title='minute')
axes[2,1].set(title='second')
#day와 hour 가 x축 글씨가 너무 촘촘해서 보이지 않아서 x축 라벨을 90도로 회전시킴
axes[1,0].tick_params(axis='x', labelrotation=90)
axes[1,1].tick_params(axis='x', labelrotation=90)
figure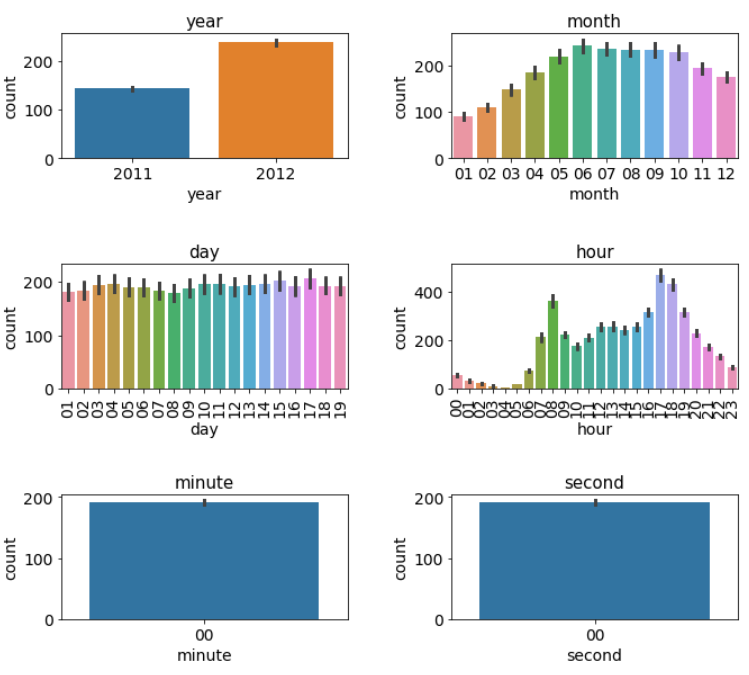
3-3) Box plot -> 범주형 데이터에 따른 수치형 데이터 정보를 나타냄
# 행렬만들기
figure, axes=plt.subplots(nrows=2 , ncols=2)
plt.tight_layout()
figure.set_size_inches(10,10)
# 그래프그리기
sns.boxplot(x='season', y='count' , data=train ,ax=axes[0,0])
sns.boxplot(x='weather', y='count' , data=train ,ax=axes[0,1])
sns.boxplot(x='holiday', y='count' , data=train ,ax=axes[1,0])
sns.boxplot(x='workingday', y='count' , data=train ,ax=axes[1,1])
# 세부설정
axes[0,0].set(title='season')
axes[0,1].set(title='weather')
axes[1,0].set(title='holiday')
axes[1,1].set(title='workingday')
#축 라벨 겹침해결
axes[0,1].tick_params(axis='x' , labelrotation=10)
3-3) Point plot
-> 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 표현
-> barplot() 막대형그래프와 동일하지만 한 화면에 여러 그래프를 그려 비교하기에 적합함
# point plot
# m행 n열 figure준비
mpl.rc('font',size=11)
figure, axes = plt.subplots(nrows=5);
figure.set_size_inches(12,18)
# 그래프 그리기 -> 시간대별 hue에 따른 데이터
sns.pointplot(x='hour' , y='count' ,data=train, hue='workingday', ax=axes[0])
sns.pointplot(x='hour' , y='count' ,data=train, hue='holiday', ax=axes[1])
sns.pointplot(x='hour' , y='count' ,data=train, hue='weekday', ax=axes[2])
sns.pointplot(x='hour' , y='count' ,data=train, hue='season', ax=axes[3])
sns.pointplot(x='hour' , y='count' ,data=train, hue='weather', ax=axes[4])
-> 위의 마지막 그래프에서 날씨가 안좋은 Heavy Rain의 경우는 이상치로 판단할 수 있으므로 , 추후에 weather ==4 인 데이터는 제거하는 것이 좋다고 판단할 수 있음.
3-4) regplot 회귀선을 포함한 산점도 그래프
-> 수치형 데이터 온도/ 체감온도 / 풍속 / 습도별 데이터는 회귀선을 포함산 산점도 그래프로 표시함
-> 회귀선을 포함한 산점도 그래프는 수치형 데이터 간 상관관계를 파악하는데 사용함
# 회귀선을 포함한 산점도 그래프
# m과 n행렬을 만듦
mpl.rc('font',size=15)
figure,axes=plt.subplots(nrows=2, ncols=2)
plt.tight_layout()
figure.set_size_inches(7,6)
#그래프 그리기
sns.regplot(x='temp' , y='count', data=train , ax=axes[0,0] , scatter_kws={'alpha' : 0.2} , line_kws={'color':'blue'})
sns.regplot(x='atemp' , y='count', data=train , ax=axes[0,1] , scatter_kws={'alpha' : 0.2} , line_kws={'color':'blue'})
sns.regplot(x='windspeed' , y='count', data=train , ax=axes[1,0] , scatter_kws={'alpha' : 0.2} , line_kws={'color':'blue'})
sns.regplot(x='humidity' , y='count', data=train , ax=axes[1,1] , scatter_kws={'alpha' : 0.2} , line_kws={'color':'blue'})
-> 위의 그래프에서 다른 것들은 어느정도 맞는 것 같으나 windspeed는 데이터와 회귀선이 다르게 표현됨을 알 수있음.
-> 이는 windspeed에 결측치가 많아서이며, 실제로는 0이 아니라 관측치가 없거나 오류로 인해 0으로 기록이 됐을 가능성이 높음. 결측치를 다른 값으로 대체하거나 피처에서 삭제해야함
3-5) 히트맵
-> temp / atemp / humidity / windspeed / count 는 수치형 데이터로 수치형 데이터 끼리의 상관관계를 파악함
# 수치형 데이터 상관관계 파악
train[['temp','atemp','humidity','windspeed','count']].corr()
-> heat map사용
#heat map 사용을 위해 mask 생성
corr_mat=train[['temp','atemp','humidity','windspeed','count']].corr()
mask=np.zeros_like(corr_mat)
# 대각행렬성분을 삭제함
mask[np.triu_indices_from(mask)]=1
# 빈 heatmap 행 / 열 삭제
corr_mat=corr_mat.iloc[1:,:-1]
mask=mask[1:,:-1]
# heatmap 그리기
figure,ax=plt.subplots()
figure.set_size_inches(10,10)
sns.heatmap(
corr_mat,
# 상관계수 표시
annot=True,
# 컬러맵
cmap='RdBu',
mask=mask,
linewidths=0.5,
# 최대값 대체
vmax=1,
# 최소값 대체
vmin=-1,
# 범례크기 줄이기
cbar_kws={"shrink" :0.5}
)
ax.set(title='Heat Map')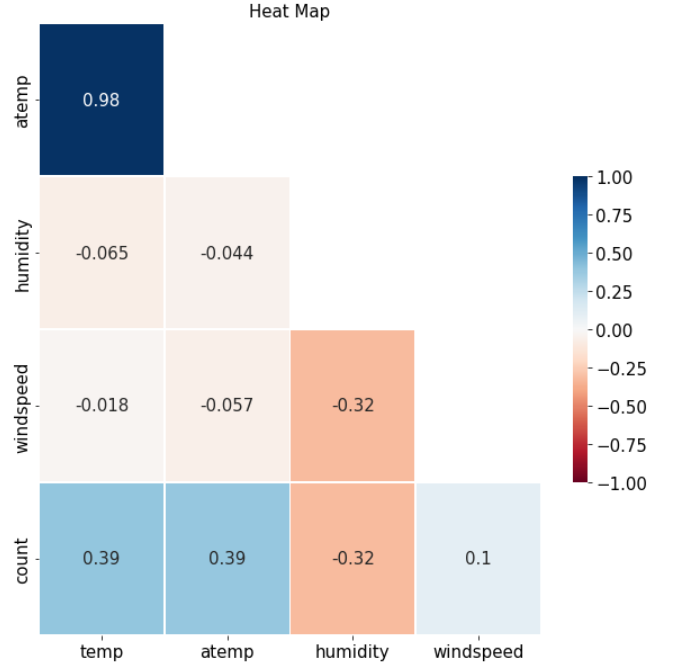
-> 위의 그래프에서 보면 온도와 count의 관계는 양의 상관관계가 있으며 습도와 count는 음의 상관관계를 보인다.
->windspeed는 0.1로 상관관계가 매우 악함으로 피처에서 제거한다.
4) BASE 모델만들기
## 위에서 분석한 자료를 바탕으로 피처 엔지니어링을 수행함
1) 피처엔지니어링 수행
1-1) 이상치 제거 및 전체 데이터 합치기
# 이상치 제거
train=train.loc[train['weather']!=4]
# 3개의 결과 다 동일함
#train.query('train !=4')
#train[train['weahter']!=4]# 데이터 합치기
# 행으로 데이터 합치기
# index를 다시 정하기 위해서 ignore_index=True 사용함
all_data_temp=pd.concat([train,test],ignore_index=True)
print(all_data_temp.shape)
all_data_temp.tail()
2-1) 파생 피처 변수 추가 (전체데이터 합쳐 놓은 dataset 사용함)
-> train은 day가 1~19일이고 , test는 20~말일 까지 이므로 train과 test가 동일하게 가지고 있지 않은 day는 필요없요없으며, minute , second는 아무런 정보를 담고 있지 않으므로 생성하지 않음
# 파생 피처 추가 -->
from datetime import datetime
#날짜 피처생성
all_data_temp['date']=all_data_temp['datetime'].apply(lambda x:x.split()[0])
#연도 피처 생성
all_data_temp['year']=all_data_temp['datetime'].apply(lambda x:x.split()[0].split("-")[0])
#월 피처 생성
all_data_temp['month']=all_data_temp['datetime'].apply(lambda x:x.split()[0].split("-")[1])
#시 피처 생성
all_data_temp['hour']=all_data_temp['datetime'].apply(lambda x:x.split()[1].split(":")[0])
#요일 피처 생성 -> 숫자형 데이터로 만듦
# 헷갈리지 말것 -> datetime이 아닌 date에서 만드어야함
all_data_temp['weekday']=all_data_temp['date'].apply(
lambda dateString : datetime.strptime( dateString, '%Y-%m-%d').weekday()
)
all_data_temp.head()
2-2) 필요 없는 피처 제거
# 필요없는 피처제거
drop_features = ['casual' ,'registered','datetime','date','windspeed','month']
all_data_temp=all_data_temp.drop(drop_features,axis=1)
all_data_temp
-> 1) casual과 registed는 테스트 데이터에 없으므로 학습에 사용불가
-> 2) datetime은 인덱스 역활이며 , date는 위에서 year / month 로 분리하였으므로 삭제함
-> 3) season이 month의 대분류를 포함하고 있기 때문에, month 피처를 삭제함
-> 4) windspeed는 count와 상관관계가 약하므로 삭제함
2) 데이터 나누기
## 데이터 나누기
# 합쳐진 데이터를 피처엔지니어링 후에 다시 나눈다.
# target인 count가 비어있으면 test 데이터이며, 값이 들어 있으면 train 데이터로 이를 활용하여 다시 분리한다.
X_train=all_data_temp[~pd.isna(all_data_temp['count'])]
X_test=all_data_temp[pd.isna(all_data_temp['count'])]
print(X_train.shape)
print(X_test.shape)
# train /test 데이터 정리
X_train=X_train.drop(columns=['count'],axis=1)
X_test=X_test.drop(columns=['count'],axis=1)
y_train=train['count']
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
## 평가 지표를 위한 함수작성 (RMSLE)
## 평가 지표를 위한 함수 작성 (RMSLE)
import numpy as np
def rmsle(y_true, y_pred ,convertExp=True):
# 지수변환 -> 앞에서 count를 log(count)로 예측할 것이므로 지수변화를 해주어야함
# 타킷값이 정규분포를 따른다면 log로 변환해서 예측할 필요가 없으며, 아래 지수변환을 수행할 필요도 없음
y_true=np.exp(y_true)
y_pred=np.exp(y_pred)
# 로그변환 후 결측값을 0으로 변환 -> np.nan_to_num 은 결측값을 다 0으로 변경함 -> 안전하게 처리하려고 사용한듯
log_true=np.nan_to_num( np.log (y_true + 1 ) )
log_pred=np.nan_to_num( np.log (y_pred + 1 ) )
# RMSLE 계산
output = np.sqrt(
np.mean(
(log_true - log_pred) **2
)
)
return output3) 모델 훈련
# 모델 훈련
# base model은 linearRegression
from sklearn.linear_model import LinearRegression
linear_reg_model=LinearRegression()
# 훈련데이터로 모델 훈련
# 타켓값을 로그변환
log_y_train=np.log(y_train)
# 모델훈련함
linear_reg_model.fit(X_train,log_y_train)# 모델 성능검증
# 원래는 test data로 해야함
# 잘되는 지 보려고 확인함
y_pred=linear_reg_model.predict(X_train)
print(f'선형 회귀 RMSLE 값 : {rmsle(log_y_train,y_pred,True):.4f}')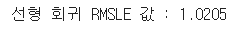
4) 결과제출 - basemodel - LinearRegression()
## 결과제출
linearreg_preds=linear_reg_model.predict(X_test)
# 앞에서 훈련데이터를 학습할 때 target -> log(target) 으로 예측하게 되어있으므로
# 위에서 X_test를 통해 나온 결과도 log(linearreg_preds) 로 되어있음 --> 지수변환필요
# 지수변환
submission['count']=np.exp(linearreg_preds)
#파일로 저장
submission.to_csv('submission.csv',index=False)
5) 성능개선모델
5-1) Ridge 모델 (L2 규제)
## Ridge 모델
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split , GridSearchCV
from sklearn import metrics
ridge_model=Ridge()
# hyper 파라미터 값
ridge_params={
'max_iter':[3000],
'alpha':[0.1,1,2,3,4,10,30,100,200,300,400,800,900,1000]
}
# 교차검증용 평가함수 (RMSLE 점수 계산)
# rmsle는 작으면 좋기때문에 greater_is_better =False로 설정함
# 여기서는 임의로 만든 평가지표를 사용함. sklearn에서는 RMSLE가 없으므로 그렇게 한듯
# metrics.make_scorer 를 통해서 별도로 만든 평가지표를 사용함
# 보통은 'accuracy' , 'f1' ,'roc_acu', 'recall' 등의 기존에 존재하는 지표를 사용함.
rmsle_scorer=metrics.make_scorer(rmsle, greater_is_better=False)
# 그리드서치 Ridge 객체생성
gridsearch_ridge_model = GridSearchCV(
estimator=ridge_model,
param_grid=ridge_params,
# 평가지표
scoring=rmsle_scorer,
cv=5
)
# 그리드서치 수행함
# 정규분포를 따르지 않으므로 log를 취한 target 값으로 예측함
log_y_train=np.log(y_train)
gridsearch_ridge_model.fit(X_train , log_y_train)
# 저장된 최적하이퍼 파라미터
print("최적파라미터", gridsearch_ridge_model.best_params_)
# 성능검증
# 성능검증
#예측
preds=gridsearch_ridge_model.best_estimator_.predict(X_train)
#평가
print("릿지 회귀 RMSLE 값",rmsle(log_y_train, preds, True))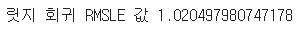
5-2) Lasso 모델 (L1 규제)
## Lasso 모델
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split , GridSearchCV
from sklearn import metrics
lasso_model=Lasso()
# hyper 파라미터 값
lasso_alpha=1/np.array([0.1,1,2,3,4,10,30,100,200,300,400,800,900,1000])
ridge_params={
'max_iter':[3000],
'alpha':lasso_alpha
}
# 교차검증용 평가함수 (RMSLE 점수 계산)
# rmsle는 작으면 좋기때문에 greater_is_better =False로 설정함
# 여기서는 임의로 만든 평가지표를 사용함. sklearn에서는 RMSLE가 없으므로 그렇게 한듯
# metrics.make_scorer 를 통해서 별도로 만든 평가지표를 사용함
# 보통은 'accuracy' , 'f1' ,'roc_acu', 'recall' 등의 기존에 존재하는 지표를 사용함.
rmsle_scorer=metrics.make_scorer(rmsle, greater_is_better=False)
# 그리드서치 Ridge 객체생성
gridsearch_lasso_model = GridSearchCV(
estimator=lasso_model,
param_grid=ridge_params,
# 평가지표
scoring=rmsle_scorer,
cv=5
)
# 그리드서치 수행함
# 정규분포를 따르지 않으므로 log를 취한 target 값으로 예측함
log_y_train=np.log(y_train)
gridsearch_lasso_model.fit(X_train , log_y_train)
# 저장된 최적하이퍼 파라미터
print("최적파라미터", gridsearch_lasso_model.best_params_)
# 성능검증
#예측
preds=gridsearch_lasso_model.best_estimator_.predict(X_train)
#평가
print("Lasso 회귀 RMSLE 값",rmsle(log_y_train, preds, True))
5-3) 랜덤 포르세트 회귀모델
# 랜덤포레스트 회귀모델
from sklearn.ensemble import RandomForestRegressor
#모델생성
randomforest_model=RandomForestRegressor()
#그리드 서치 객체생성
rf_params={
'random_state':[42],
'n_estimators':[100,120,140]
}
gridsearch_random_forest_model=GridSearchCV(
estimator=randomforest_model,
param_grid=rf_params,
scoring=rmsle_scorer,
cv=5
)
#그리드 서치수행
log_y_train=np.log(y_train)
gridsearch_random_forest_model.fit(X_train,log_y_train)
# 최적파라미터
print("랜덤포레스트 최적파라미터",gridsearch_random_forest_model.best_params_)
#모델성능검증
#예측
preds=gridsearch_random_forest_model.best_estimator_.predict(X_train)
#평가
print("랜덤포레스트 RMSLE 값",rmsle(log_y_train,preds,True))
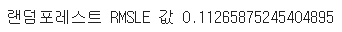
## 최종결과 제출전 예측된 target 값이 과대적합 없이 잘 에측 되어있는지 분포도를 확인함
( 기존의 train데이터의 target의 분포와 test 데이터로 예측한 target의 분포를 확인함)
-> 분포가 비슷하다면 예측이 상대적으로 잘되었다고 생각할 수 있음
import seaborn as sns
import matplotlib.pyplot as plt
# test 데이터를 통해 예측한값
#예측
preds_test=gridsearch_random_forest_model.best_estimator_.predict(X_test)
firgure, axes= plt.subplots(ncols=2)
plt.tight_layout()
figure.set_size_inches(10,4)
sns.histplot(data=y_train, bins=50 ,ax=axes[0])
axes[0].set(title='Train target')
sns.histplot(data=np.exp(preds_test), bins=50 , ax=axes[1])
axes[1].set(title='Test Target RandomForeset')
# 결과제출
# 결과제출
submission['count']=np.exp(preds_test)
submission.to_csv('submission.csv',index=False)
'Python 데이터분석' 카테고리의 다른 글
| [데이터분석실습][회귀-LGBM/XGB] 향후 판매량 예측 _ 회귀 (0) | 2022.07.12 |
|---|---|
| [데이터분석실습][이진분류_LR]_Categorical Feature Encoding Challenge (0) | 2022.07.03 |
| [데이터전처리]LabelEncoding / OneHotEncoding (0) | 2022.06.29 |
| [데이터분석실습][이진분류_결정트리]소득 예측 모델 만들기 (0) | 2022.06.28 |
| [데이터분석실습]통계 분석 기법을 이용한 가설검정 (0) | 2022.06.28 |



