
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- GYM
- coding
- kaggle
- Instagrame clone
- FirebaseV9
- selenium
- 카트폴
- 클론코딩
- ReactNative
- 앱개발
- 머신러닝
- TeachagleMachine
- python
- 강화학습 기초
- 강화학습
- 리액트네이티브
- 데이터분석
- 전국국밥
- 딥러닝
- App
- Ros
- 사이드프로젝트
- pandas
- Reinforcement Learning
- expo
- 조코딩
- clone coding
- redux
- React
- JavaScript
- Today
- Total
qcoding
[데이터분석실습][회귀-LGBM/XGB] 향후 판매량 예측 _ 회귀 본문
머신러닝·딥러닝 문제해결 전략 - 교보문고
캐글 수상작 리팩터링으로 배우는 문제해결 프로세스와 전략 | 이 책은 수많은 캐글 수상자의 노트북을 수집/분석하여 여러분께 공통된 문제해결 패턴을 안내해줍니다. 총 7개의 경진대회를 이
www.kyobobook.co.kr
## 해당 교재로 학습 후 실습을 진행하였습니다.
https://www.kaggle.com/competitions/competitive-data-science-predict-future-sales
Predict Future Sales | Kaggle
www.kaggle.com
1) 데이터 가져오기
import pandas as pd
data_path= '/kaggle/input/competitive-data-science-predict-future-sales/'
sales_train = pd.read_csv(data_path + 'sales_train.csv')
shops = pd.read_csv(data_path + 'shops.csv')
items = pd.read_csv(data_path +'items.csv')
item_categories = pd.read_csv(data_path + 'item_categories.csv')
test= pd.read_csv(data_path + 'test.csv')
submission= pd.read_csv(data_path + 'sample_submission.csv')
sales_train.head()--> date_block_sum은 날짜 중 월의 구분자이며 02.01.2013은 일/월/연의 순서로 1월은 0번에 해당함. 월별 판매량을 구하는 것이므로 date의 일결과는 필요없이 date_block_num만 사용함
--> item_cnt_day는 당일 판매량을 나타내며, 일을 기준으로 하루에 item_id를 가진 몇 개를 팔았는 가를 나타냄. 월별 판매량을 구하는 것이므로 date_block_num으로 그륩화하여 shop_id에 해당하는 item_id를 합친 값이 월별판매량이 됨을 알 수 있음.
## sales_train

## 데이터 행의 갯수나 열의 갯수가 너무 많은 non-null의 갯수가 표시되지 않으므로
## show_counts=True 옵션을 사용함
sales_train.info(show_counts=True)
## shops
shops.head()
-> 상점명은 러시아어로 되어있으며, 상점명에서도 새로운 피처를 추출할 예정이며, 첫 단어는 도시를 의미함.
또한 shop_id는 sales_train에도 있으며 병합이 가능함.
shops.info()

## items
items.head()
-> item_id로 sales_train 데이터와 병합가능함.
items.info()
## item_categories
--> item_categories 에서 첫번째 단어는 대분류를 뜻하며 새로운 피처를 추출할 예정.
item_categories.head()
item_categories.info()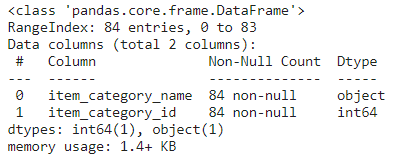
## test
# test
test.head()
2) 데이터 병합하기
-> train = sales_train + shops --> shop_id
--> train = train + items --> item_id
--> train = train + item_categories --> item_category_id
### 데이터 병합하기
train = sales_train.merge(shops , on='shop_id', how='left')
train = train.merge(items , on='item_id' , how='left')
train = train.merge(item_categories , on='item_category_id' , how='left')
train.head()
def resumetable(df):
print(f'데이터셋 형상 {df.shape}')
summary=pd.DataFrame(df.dtypes, columns=['데이터타입'])
# reset_index()를 하면 기존에 index 였던 피처 열이 뒤로 가면서 "index" 라는 column 이름이 되고 앞에 새로운 숫자 인덱스가 생김
summary=summary.reset_index()
summary=summary.rename(columns={'index' : '피처'})
summary['결측값 갯수'] = df.isnull().sum().values
summary['교윳값 갯수'] = df.nunique().values
# loc를 통해서 index 이름으로 가져옴
summary['첫번째 값']=df.iloc[0].values
summary['두번째 값']=df.iloc[1].values
summary['세번째 값']=df.iloc[2].values
return summary
3) 데이터 시각화
# 일별 판매량
## 데이터 시각화
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
sns.boxplot(y='item_cnt_day', data=train)
--> 위와 같이 보이는 것은 이상치가 과도크고 많아서 1 / 2 / 3 사분위 값이 납작해진 것.
## 판매가 (상품가격)
# 판매가
sns.boxplot(y='item_price' , data=train)
## 그륩화
#월별 판매량
--> 앞에서 date_block num 이 각 월에 해당하는 index 이므로 이를 그륩화하여 item_cnt_day를 합하여 월별 판매량을 나타냄
group = train.groupby('date_block_num' ,as_index=False ).agg(
item_cnt_sum_per_month=('item_cnt_day' , 'sum')
)
group.head()
# 월별 판매량 그래프
mpl.rc('font', size=13)
figure, ax =plt.subplots()
figure.set_size_inches(11,5)
# 월별 총 상품 판매량
group_month_sum = train.groupby('date_block_num' ,as_index=False ).agg(
item_cnt_sum_per_month=('item_cnt_day' , 'sum')
)
# 월별 총 상품 판매량 막대그래프
sns.barplot(x='date_block_num' , y='item_cnt_sum_per_month' , data=group_month_sum)
ax.set(
title = "Item counts by month",
xlabel = 'Date block number',
ylabel = 'Monthly item counts'
)
#상품 분류별 판매량
-> 상품의 갯수확인 결과 총 84개로 너무 많아서 그리기 어려우므로 판매량이 10,000개를 초과하는 상품만 추출해서 그래프 생성함
train['item_category_id'].nunique()mpl.rc('font',size=13)
figure , ax = plt.subplots()
figure.set_size_inches(11,5)
# 상품 분류별 총 상품 판매량
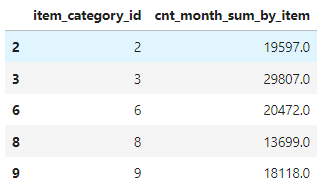
group_cat_sum = train.groupby('item_category_id', as_index=False).agg(
cnt_month_sum_by_item = ('item_cnt_day', 'sum')
)
group_cat_sum
# 10,000개 넘는 상품을 선택함.
group_cat_sum_fil=group_cat_sum.loc[group_cat_sum['cnt_month_sum_by_item']>10000]
group_cat_sum_fil.head()
group_cat_sum_fil.shape--> 총 42개의 상품이 선택됨.
# 그래프 그리기
sns.barplot(x='item_category_id' , y='cnt_month_sum_by_item' , data=group_cat_sum_fil)
ax.set(
title = 'Item category counts by month',
xlabel = 'item_category_id',
ylabel = 'cnt_month_sum_by_item'
)
ax.tick_params(axis='x', labelrotation=90)
## 상점별 판매량
## 상점별 판매량
mpl.rc('font',size=13)
figure,ax = plt.subplots()
figure.set_size_inches(11,6)
# shop id로 그륩화하여 월별 판매량 확인
group_shop = train.groupby('shop_id', as_index=False).agg(
item_month_sum_by_shop = ('item_cnt_day','sum' ) )
# 판매량이 10,000 개가 넘는 shop 만 확인
group_shop_fil = group_shop.loc[group_shop['item_month_sum_by_shop']>10000]
#그래프 그리기
sns.barplot(x='shop_id',y='item_month_sum_by_shop',data=group_shop)
ax.set(
title = 'Shop counts by month',
xlabel='shop_id',
ylabel='monthly sum'
)
ax.tick_params(axis='x', labelrotation = 90 )
4) base모델 만들기
1) 데이터 불러오기
## base line 모델 만들기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
data_path= '/kaggle/input/competitive-data-science-predict-future-sales/'
sales_train = pd.read_csv(data_path + 'sales_train.csv')
shops = pd.read_csv(data_path + 'shops.csv')
items = pd.read_csv(data_path +'items.csv')
item_categories = pd.read_csv(data_path + 'item_categories.csv')
test= pd.read_csv(data_path + 'test.csv')
submission= pd.read_csv(data_path + 'sample_submission.csv')2) 피처엔지니어링 : 피처명 한글화
## 피처 엔지니어링 : 피처명 한글화
sales_train = sales_train.rename(
columns = {
'date' : '날짜',
'date_block_num' : '월id',
'shop_id': '상점id',
'item_id' : '상품id',
'item_price' : '판매가',
'item_cnt_day' : '판매량'
}
)
sales_train.head()
## shops 변경
shops=shops.rename(
columns={
'shop_name' : '상점명',
'shop_id': '상점id'
})
shops.head()
# items 변경
items=items.rename(
columns={
'item_name' : '상품명',
'item_id': '상품id',
'item_category_id':'상품분류id'
})
items.head()
#item_categories 변경
item_categories=item_categories.rename(
columns={
'item_categories_name' : '상품분류명',
'item_categories_id': '상품분류id',
})
item_categories.head()
## tets 피처명 변경
test=test.rename(
columns={
'shop_id' : '상점id',
'item_id' : '상품id'
}
)
test.head()
3) 피처엔지니어링 : 데이터 다운 캐스팅
-> 다운캐스팅은 더 작은 데이터 타입으로 변환하는 작업을 의미하며, 주어진 데이터 크기에 딱 맞는 타입으로 변경해주기 위한 작업.
def downcast(df,verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
dtype_name = df[col].dtype.name
if dtype_name == 'object':
pass
elif dtype_name == 'bool':
df[col] = df[col].astype('int8')
elif dtype_name.startswith('int') or (df[col].round() == df[col]).all():
df[col] = pd.to_numeric(df[col], downcast = 'integer')
else:
df[col] = pd.to_numeric(df[col], downcast = 'float')
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(f'{100 * (start_mem - end_mem)/start_mem : .1f}% 압축됨')
return dfall_df = [sales_train , shops , items , item_categories, test]
for df in all_df:
df = downcast(df)
4) 피처 엔지니어링 : 데이터 조합생성
-> test 데이터에서는 상점 id / 상품 id 의 값으로 예측해야 하므로, 월별 상점 id / 상품 id로 된 데이터 조합이 필요함.
월id별로 한번이라도 등장한 상품 id와 상점 id가 있다면 그것들의 조합이 필요함. 상점 id는 있으나 상품 id가 없는 경우에는 채워서 0의 판매량으로 만들어줌.
# 데이터 조합 생성
from itertools import product
train = []
for i in sales_train['월id'].unique():
# 월id 에 해당하는 모든 상점 id를 선택함
all_shop = sales_train.loc[sales_train['월id']==i , '상점id'].unique()
# 월 id에 해당하는 모든 상품 id를 선택함
all_item = sales_train.loc[sales_train['월id']==i , '상품id'].unique()
train.append(
np.array(
# produt를 사용하여 월id , 상점 id, 상품 id의 조합을 생성함
list(product([i], all_shop , all_item))
)
)
# 기준피처설정
idx_features=['월id','상점id','상품id']
# list 타입의 train을 DataFrame 형태로 변경
train = pd.DataFrame(
# 각각의 list의 배열 요소를 세로로 붙임
np.vstack(train),columns= idx_features
)
train
5) 피처 엔지니어링 : 타깃값(월간 판매량)추가
## 월간 판매량을 구함
idx_features=['월id','상점id','상품id']
group = sales_train.groupby(idx_features, as_index=False).agg(
월간판매량 = ('판매량','sum')
)
group
## train과 group 데이터 병함
## 데이터 병합하기
# 없는 부분은 기존에 없는 데이터이므로 판매량을 후에 0으로 변경함
train = train.merge(group , on=idx_features , how='left')
train
## 필요없는 데이터는 메모리 절약 차원에서 가비지 컬렉션을 통해 제거함
## 가비지 컬렉션
# 필요없는 group 데이터 삭제함
import gc
del group
gc.collect()
6) 피처 엔지니어링 : 테스트 데이터 이어 붙이기
-> 지금 train 데이터에 shop / items/ item_categories 를 병합할 때 test 에도 적용해야 함으로 train과 test를 이어 붙인후에 데이터를 처리함
## 테스트 데이터에는 월id 피처가 없으므로 생성해 주어야함
## 테스트 데이터는 2015년 11월 판매 기록이므로 34로 설정함
test['월id']=34# train과 test 이어 붙이기
all_data = pd.concat(
[train, test.drop(columns=['ID'],axis=1)],
ignore_index=True,
# 이어 붙이는 데 기준이 되는 피처
keys=idx_features
)
# 앞에서 생긴 결측치를 0으로 대체
all_data=all_data.fillna(0)
all_data
7) 피처 엔지니어링 : 나머지 데이터 병합 (최종데이터 생성)
### 데이터 병합하기
all_data = all_data.merge(shops , on='상점id', how='left')
all_data = all_data.merge(items , on='상품id' , how='left')
all_data = all_data.merge(item_categories , on='상품분류id' , how='left')
#데이터 다운캐스팅
all_data=downcast(all_data)
# 가비지 컬렉션
import gc
del shops , items , item_categories
gc.collect
all_data.head()
## 상점명 상품명 상품 분류명 삭제 --> 상점 id 와 상품 id , 상품분류id 와 일대일 대응 되므로 삭제함
all_data = all_data.drop(columns =['상점명','상품명','상점분류명'],axis=1)
all_data.head()
8) 피처 엔지니어링 : 데이터 분리
- 훈련데이터 : 2013년 1월 ~ 2015년 9월 ( 월 id ~32까지)
- 검증데이터 : 2015년 10월 (월 id =33)
- 테스트데이터 : 2015년 11월 (월id=34)
## 데이터 분리
#훈련데이터
X_train = all_data.loc[all_data['월id'] < 33]
X_train = X_train.drop(columns = ['월간판매량'], axis=1)
#검증데이터
X_valid = all_data.loc[all_data['월id'] == 33]
X_valid = X_valid.drop(columns = ['월간판매량'], axis=1)
#테스트데이터
X_test = all_data.loc[all_data['월id'] == 34]
X_test = X_test.drop(columns = ['월간판매량'], axis=1)
#타켓값 설정
# 훈련데이터
y_train = all_data.loc[all_data['월id'] < 33 , '월간판매량']
# 판매량값을 0~20으로 제한시킴 <- 이번 경진대회 공지사항에 나와있음
y_train = y_train.clip(0,20)
# 검증데이터
y_valid = all_data.loc[all_data['월id'] == 33 , '월간판매량']
# 판매량값을 0~20으로 제한시킴 <- 이번 경진대회 공지사항에 나와있음
y_valid = y_valid.clip(0,20)
print("훈련데이터" , X_train.shape)
print("검증데이터" , X_valid.shape)
print("테스트" , X_test.shape)
print("타켓_훈련" , y_train.shape)
print("타켓 검증", y_valid.shape)
9) 모델 훈련 및 검증하기
-> light gbm을 사용하며 범주형데이터는 train() 메서드 내에 categorical_feature 파라미터에 넣어 주어야 하며 현재데이터에서는 상점id , 상품 id, 상품분류 id 로 3개가 있지만 , 상품id의 고윳값 갯수가 너무 많은 관계로 light GBM 문서에서는 고윳값 갯수가 너무 많은 범주형 데이터는 수치형으로 취급해야 성능이 잘 나온다고 함으로 cateogorical_feature에는 '상점id'와 '상품분류id'만 넣음
#light gbm 사용하기
import lightgbm as lgb
# 파라미터
params={
'metric' : 'rmse',
'num_leaves': 255,
'learning_rate' : 0.01,
'force_col_wise' : True,
'random_state' : 10
}
# 범주형 피처설정
cat_features = ['상점id' , '상품분류id']
# lightGbm 용 훈련 및 검증 데이터 셋
dtrain = lgb.Dataset(X_train, y_train)
dvalid = lgb.Dataset(X_valid , y_valid)
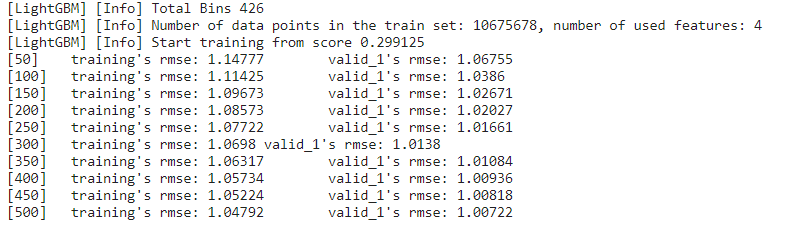
##모델훈련
lgb_model = lgb.train(
params = params,
train_set = dtrain,
num_boost_round=500,
valid_sets=(dtrain,dvalid),
categorical_feature = cat_features,
verbose_eval=50
)
10) 제출하기
## 예측 및 결과제출
#예측
preds = lgb_model.predict(X_test).clip(0,20)
#제출파일생성
submission['item_cnt_month']=preds
submission.to_csv('submission.csv',index=False)5) 성능개선
1) 피처엔지니어링
## base line 모델 만들기
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
data_path= '/kaggle/input/competitive-data-science-predict-future-sales/'
sales_train = pd.read_csv(data_path + 'sales_train.csv')
shops = pd.read_csv(data_path + 'shops.csv')
items = pd.read_csv(data_path +'items.csv')
item_categories = pd.read_csv(data_path + 'item_categories.csv')
test= pd.read_csv(data_path + 'test.csv')
submission= pd.read_csv(data_path + 'sample_submission.csv')## 피처 엔지니어링 : 피처명 한글화
sales_train = sales_train.rename(
columns = {
'date' : '날짜',
'date_block_num' : '월id',
'shop_id': '상점id',
'item_id' : '상품id',
'item_price' : '판매가',
'item_cnt_day' : '판매량'
}
)
## shops 변경
shops=shops.rename(
columns={
'shop_name' : '상점명',
'shop_id': '상점id'
})
# items 변경
items=items.rename(
columns={
'item_name' : '상품명',
'item_id': '상품id',
'item_category_id':'상품분류id'
})
#item_categories 변경
item_categories=item_categories.rename(
columns={
'item_category_name' : '상품분류명',
'item_category_id': '상품분류id',
})
## tets 피처명 변경
test=test.rename(
columns={
'shop_id' : '상점id',
'item_id' : '상품id'
}
)def downcast(df,verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
dtype_name = df[col].dtype.name
if dtype_name == 'object':
pass
elif dtype_name == 'bool':
df[col] = df[col].astype('int8')
elif dtype_name.startswith('int') or (df[col].round() == df[col]).all():
df[col] = pd.to_numeric(df[col], downcast = 'integer')
else:
df[col] = pd.to_numeric(df[col], downcast = 'float')
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(f'{100 * (start_mem - end_mem)/start_mem : .1f}% 압축됨')
return df
all_df = [sales_train , shops , items , item_categories, test]
for df in all_df:
df = downcast(df)## sales_trian 이상치 제거 및 전처리
## sales _train 이상치 제거 및 전처리
## 판매가와 판매량의 이상치 제거
# 판매가가 0보다 크고 50000보다 작은 데이터 추출
sales_train = sales_train.loc[(sales_train['판매가']>0) & (sales_train['판매가']<50000)]
# 판매량이 0보다 크고 1000보다 작은 데이터 추출
sales_train = sales_train.loc[(sales_train['판매량']>0) & (sales_train['판매량']< 1000)]
sales_train
##상정명을 가지고 전처리
# 같은 상점명인데 다르게 표시되어 있는 것을 합침
print(shops.loc[0,'상점명'] , "||" , shops.loc[57,'상점명'])
print(shops.loc[1,'상점명'] , "||" , shops.loc[58,'상점명'])
print(shops.loc[10,'상점명'] , "||" , shops.loc[11,'상점명'])
print(shops.loc[39,'상점명'] , "||" , shops.loc[40,'상점명'])
## sales_train 에서 상점 ID 수정
sales_train.loc[sales_train['상점id']==0,'상점id']=57
sales_train.loc[sales_train['상점id']==1,'상점id']=58
sales_train.loc[sales_train['상점id']==10,'상점id']=11
sales_train.loc[sales_train['상점id']==39,'상점id']=40
# test 데이터에서 상점 id 수정
test.loc[test['상점id']== 0 , '상점id'] = 57
test.loc[test['상점id']== 1 , '상점id'] = 58
test.loc[test['상점id']== 10 , '상점id'] = 11
test.loc[test['상점id']== 39 , '상점id'] = 40### shops 파생 피처 생성 및 인코딩
## shops 파생 피처 생성 및 인코딩
## 상점명의 첫 단어는 상점이 위치는 도시를 뜻함
shops['도시']=shops['상점명'].apply(lambda x:x.split()[0])
shops['도시'].unique()# 느낌표가 있는 도시 전처리
shops.loc[shops['도시'] == '!Якутск','도시']='Якутск'
shops['도시'].unique()도시명은 범주형 피처 이므로 머신러닝 모델은 문자를 인식하지 못함. 숫자로 인코딩 필요
--> 레이블 인코딩 사용 , 레이블인코딩은 값이 큰 것이 연관성이 높다고 생각하여 머신러닝에 영향이 좋지 않지만 트리기반 모델을 사용할 땐 레이블 인코딩을 해도 지장이 없음. 트리기반 모델 특성상 분기를 반복하면서 피처 정보를 반영하므로 단점이 무마됨. 여기서 사용하는 boost 알고리즘은 트리기반임
## 도시명은 범주형 피처 이므로 문자를 인식하지 못함
## 레이블 인코딩
from sklearn.preprocessing import LabelEncoder
#레이블 인코더 생성
label_encoder = LabelEncoder()
#도시 피처 레이블 인코딩
shops['도시']=label_encoder.fit_transform(shops['도시'])
# 필요없는 상점명 피처제거
shops = shops.drop(columns=['상점명'] , axis=1)
shops.head()
### items 파생 피처 생성
--> 첫판매월 피처를 sales_train을 통해서 구함
sales_train.groupby('상품id',as_index=False).agg(
첫판매월 = ('월id','min')
)
# 상품이 판매되었던 첫 달을 구함
# sales_train으로 부터 계산함
items['첫판매월']=sales_train.groupby('상품id',as_index=False).agg(
첫판매월 = ('월id','min')
)['첫판매월']
# 결측값 확인함
items.isna().sum()
결측값이 있다는 얘는 해당 상품이 한번도 판매된 적이 없다는 의미임.
한번도 판매된적이 없는 상품은 테스트데이터에서 예측해야 되는 2015년 11월 (월id = 34)가 첫 판매일이라고 대체함.
## 테스트 데이터로 예측하는 시점이 첫 판매일이라고 생각하여 데이터 대체함
items.loc[items['첫판매월'].isna()]
## 34로 대체함
items['첫판매월']=items['첫판매월'].fillna(34)
items.isna().sum()
### item_categories 파생피처 생성 및 인코딩
## item_categories 파생 피처 생성 및 인코딩
# 상품 분류명의 첫 단어가 범주 대분류 라는 것을 발견함
item_categories['대분류']=item_categories['상품분류명'].apply(lambda x:x.split()[0])
item_categories['대분류'].value_counts()
-> 5개 미만의 경우 etc로 만들어 대분류의 고윳값 갯수를 줄임
## 대분류의 갯수가 5개 미만은 etc로 처리함
def make_etc(x):
if len(item_categories.loc[item_categories['대분류']==x])>=5:
return x
else:
return 'etc'
item_categories['대분류']=item_categories['대분류'].apply(make_etc)
item_categories
## label encoding
from sklearn.preprocessing import LabelEncoder
# 레이블 인코더 생성
label_encdoer = LabelEncoder()
#대분류 피처 레이블 인코딩
item_categories['대분류']= label_encoder.fit_transform(item_categories['대분류'])
item_categories['대분류'].unique()
# 상품분류명 피처 제거
item_categories=item_categories.drop(columns = ['상품분류명'], axis=1)
item_categories
## 데이터 조합
# 데이터 조합 생성
from itertools import product
train = []
for i in sales_train['월id'].unique():
# 월id 에 해당하는 모든 상점 id를 선택함
all_shop = sales_train.loc[sales_train['월id']==i , '상점id'].unique()
# 월 id에 해당하는 모든 상품 id를 선택함
all_item = sales_train.loc[sales_train['월id']==i , '상품id'].unique()
train.append(
np.array(
# produt를 사용하여 월id , 상점 id, 상품 id의 조합을 생성함
list(product([i], all_shop , all_item))
)
)
# 기준피처설정
idx_features=['월id','상점id','상품id']
# list 타입의 train을 DataFrame 형태로 변경
train = pd.DataFrame(
# 각각의 list의 배열 요소를 세로로 붙임
np.vstack(train),columns= idx_features
)
train
## 파생 피처 생성 및 데이터 merge
## 파생 피처 생성
# 월간 판매량 / 평균 팡매가 피처 생성함
# 기준피처설정
idx_features=['월id','상점id','상품id']
group = sales_train.groupby(idx_features , as_index=False).agg(
# 월간판매량 생성
월간판매량 = ('판매량','sum'),
# 평균판매가 생성
평균판매가 = ('판매가','mean')
)
# train 데이터에 merge
train = train.merge(group , on=idx_features , how='left')
train.head()
위에서 생성된 nan은 해당 상품이 한번도 판매된 적이 없어서 판매량과 평균 판매가 NaN으로 나옴. 결측값은 0으로 대체함
# 기준일당 판매 건수 파생피처 생성 --> 하루에 한건이라도 판매량 값이 있으면 1 이거나 1보다 큼 , 없으면 0
## 기준 피처별 상품 판매건수
# 기준피처설정
idx_features=['월id','상점id','상품id']
group = sales_train.groupby(idx_features , as_index=False).agg(
판매건수 = ('판매량','count')
)
# train과 병합
train = train.merge(group , on=idx_features , how='left')
train.head()
## 데이터 합치기
# 테스트 데이터 이어 붙이기
## test data 이어 붙이기
# test data에 없는 월 id 피처 생성
test['월id']=34
# train과 test 이어 붙이기
all_data = pd.concat(
[train, test.drop(columns=['ID'],axis=1)],
ignore_index=True,
# 이어 붙이는 데 기준이 되는 피처
keys=idx_features
)
# 앞에서 생긴 결측치를 0으로 대체
all_data=all_data.fillna(0)
all_data
### 데이터 병합하기
all_data = all_data.merge(shops , on='상점id', how='left')
all_data = all_data.merge(items , on='상품id' , how='left')
all_data = all_data.merge(item_categories , on='상품분류id' , how='left')
#데이터 다운캐스팅
all_data=downcast(all_data)
# 가비지 컬렉션
import gc
del shops , items , item_categories
gc.collect
all_data.head()

## 시차 피처 생성
-> time lag 피처 생성으로 시계열 데이터 문제에서 자주 만드는 파생 피처.
-> 기준으로 삼을 피처를 선정함. '월간 평균 판매량' 이 타깂값과 연관성이 있을 것이므로 선정하고
## 시차 피처 생성
def add_mean_features(df, mean_features, idx_features):
# 기준피처확인
# assert 뒤에나오는 값이 false면 에러생김
assert ((idx_features[0]=='월id') and len(idx_features) in [2,3])
# 파생 피처명 설정
if len(idx_features)==2:
feature_name = idx_features[1] + '별 평균 판매량'
else:
feature_name = idx_features[1]+""+idx_features[2]+'별 평균 판매량'
#기준 피처를 토대로 그륩화해 월간 평간 평균 판매량 구하기
group = df.groupby(idx_features , as_index=False).agg(
{'월간판매량' : 'mean'}
)
group=group.rename(columns ={
'월간판매량' : feature_name
})
#df 와 group 병합
df=df.merge(group , on=idx_features , how='left')
#데이터 다운 캐스팅
df= downcast(df, verbose=False)
#새로 만든 feature_name 피처명을 mean_features 리스트에 추가
mean_features.append(feature_name)
# #가비지 컬렉션
# del group
# gc.collect()
return df, mean_features# 그륩화 기준 피처 중 상품 id가 포함된 파생 피처명을 담을 리스트
item_mean_features=[]
# ['월 id' , '상품id'] 로 그륩화한 월간 평균 판매량 파생 피처 생성
all_data, item_mean_features = add_mean_features(
df= all_data,
mean_features=item_mean_features,
idx_features=['월id', '상품id']
)
# ['월 id' , '상품id' ,' 도시'] 로 그륩화한 월간 평균 판매량 파생 피처 생성
all_data, item_mean_features = add_mean_features(
df= all_data,
mean_features=item_mean_features,
idx_features=['월id', '상품id','도시']
)
all_data
item_mean_features
# 그륩화 기준 피처 중 상품 id가 포함된 파생 피처명을 담을 리스트
shop_mean_features=[]
# ['월 id' , '상품id' ,' 상품분류id'] 로 그륩화한 월간 평균 판매량 파생 피처 생성
all_data, item_mean_features = add_mean_features(
df= all_data,
mean_features=shop_mean_features,
idx_features=['월id', '상점id','상품분류id']
)
all_data
shop_mean_features
--> 위에서 lag를 위해서 새롭게 만든 피처는 총 3개로
1) 상품 id별 평균 판매량 => group =['월id' , '상품id']
2) 상품 id별 도시별 평균 판매량 => group =['월id' , '상품id' ,'도시']
3) 상품id 별 상품분류별 평균 판매량 => group =['월id' ,'상점id' , '상품분류id']
### 시차 피처 생성
1) 기준 피처와 시찻값을 구하려는 피처를 정함
-> 기준피처 => '월id ' ,'상점id' , '상품id'
-> 시찻값을 구하려는 피처 => '월간판매량'
2) 기준피처의 복사본을 만들어서 '월간판매량_시차1'을 만들고 월 id는 한달씩 미뤄지는 것이므로 1씩 더해줌
3) 기준피처가 되는 df와 복사한 df를 기준피처를 토대로 병합함
## 시차 피처 생성 원리 및 함수 구현
def add_lag_features(df, lag_features_to_clib , idx_features , lag_feature, nlags=3 , clip=False):
# 시차 피처 생성에 필요한 DataFrame 부분복사
df_temp = df[idx_features + [lag_feature]].copy()
# 시차 피처 생성
for i in range(1,nlags+1):
# 시차 피처명
lag_feature_name = f'{lag_feature}시차_{i}'
#df_temp 열 이름 설정
df_temp.columns=idx_features + [lag_feature_name]
#df_temp의 date_block_num 피처에 i 더하기
df_temp['월id']+=i
#idx feature를 기준으로 df와 df_temp 병합하기
df=df.merge(df_temp.drop_duplicates(),
on=idx_features,
how='left'
)
# 결측값 0으로 대체
df[lag_feature_name] = df[lag_feature_name].fillna(0)
# 0~20 사이로 제한할 피처명을 lag_feature_to_clip에 추가
if clip:
lag_features_to_clib.append(lag_feature_name)
# 데이터 다운캐스트
df=downcast(df,False)
#가비지 컬렉션
del df_temp
gc.collect()
return df , lag_features_to_clip## 시차 - 월간판매량
## 시차 생성 - 월간판매량
lag_features_to_clip=[]
# 기준피처
idx_features=['월id','상점id','상품id']
# idx_features를 기준으로 월간 판매량의 세달치 시차 피처 생성
all_data , lag_features_to_clip =add_lag_features(
df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features = idx_features,
lag_feature='월간판매량',
nlags=3,
# 월간판매량은 타깃값이므로 0~20 제한 필요함 --> clip=True로 하여 lag_features_to_clip에 변수저장함
clip=True
)all_data.head().T
lag_features_to_clip
## 시차 - 판매건수 , 평균판매가
## 시차생성 - 판매건수 , 평균 판매가
# 기준피처
idx_features=['월id','상점id','상품id']
# idx_features를 기준으로 월간 판매건수의 세달치 시차 피처 생성
all_data , lag_features_to_clip =add_lag_features(
df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features = idx_features,
lag_feature='판매건수',
nlags=3,
# 판매건수는 타겟값이 아니므로 값을 고정할 필요없음
clip=False
)
# idx_features를 기준으로 월간 판매량의 세달치 시차 피처 생성
all_data , lag_features_to_clip =add_lag_features(
df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features = idx_features,
lag_feature='평균판매가',
nlags=3,
# 평균판매가는 타겟값이 아니므로 값을 고정할 필요없음
clip=False
)
all_data.head().T
## 시차생성 - 평균판매량
## 시차생성 - 평균 판매가
# 기준피처
idx_features=['월id','상점id','상품id']
##앞에서 저장한
# 1) 상품 id별 평균 판매량 => group =['월id' , '상품id'] ------ item_mean_features
# 2) 상품 id별 도시별 평균 판매량 => group =['월id' , '상품id' ,'도시'] ------ item_mean_features
# 3) 상품id 별 상품분류별 평균 판매량 => group =['월id' ,'상점id' , '상품분류id'] ------ shop_mean_features
# 에 대한 시차적용함
for item_mean_featrue in item_mean_features:
# idx_features를 기준으로 월간 판매건수의 세달치 시차 피처 생성
all_data , lag_features_to_clip =add_lag_features(
df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features = idx_features,
lag_feature=item_mean_featrue,
nlags=3,
# 위에 id별 평균 판매량과 , 도시별 평균판매량은 타깃값과 같이 월평균판매량이므로 0~20 제한 필요함
clip=False
)
# 시차를 위해 사용하고 기존에 있는 1) , 2)의 변수제거
all_data = all_data.drop(columns=item_mean_features , axis=1)
#all_data.head().T
## shops
for shop_mean_featrue in shop_mean_features:
# idx_features를 기준으로 월간 판매건수의 세달치 시차 피처 생성
all_data , lag_features_to_clip =add_lag_features(
df=all_data,
lag_features_to_clip = lag_features_to_clip,
idx_features = idx_features,
lag_feature=shop_mean_featrue,
nlags=3,
# 3)에 대항하는 값으로 타겟값에 영향을 주는 값
clip=True
)
# 시차를 위해 사용하고 기존에 있는 1) , 2)의 변수제거
all_data = all_data.drop(columns=shop_mean_features , axis=1)
all_data.head().T
## 결측값을 가지고 있는 index 삭제 - > 여기서는 행 삭제임
all_data=all_data.drop(all_data.loc[all_data['월id']<3].index)
### 기타 피처 엔지니어링
# 월간 판매량 시차 피처들의 평균
## 월간 판매량 시차 피처들의 평균
all_data['월간판매량시차평균']=all_data[['월간판매량시차_1','월간판매량시차_2','월간판매량시차_3']].mean(axis=1)
#0~20 사이로 값 제한
all_data[lag_features_to_clip + ['월간판매량','월간판매량시차평균']] =\
all_data[lag_features_to_clip + ['월간판매량','월간판매량시차평균']].clip(0,20)# 시차 변화량
--> 여기서 replace([np.inf , -np.inf], np.nan).fillna(0) 은 값을 0으로 나누는 상황을 대처하기 위한 방어 코드로, 양수를 0으로 나누면 np.inf 가 되고 음수를 0으로 나누면 -np.inf 가 되므로 이값을 np.nan으로 바꾼 뒤 0을 채운다.
#시차 변화량
all_data['시차변화량1']=all_data['월간판매량시차_1'] / all_data['월간판매량시차_2']
all_data['시차변화량1'] = all_data['시차변화량1'].replace([np.inf , -np.inf], np.nan).fillna(0)
all_data['시차변화량2']=all_data['월간판매량시차_2'] / all_data['월간판매량시차_3']
all_data['시차변화량2'] = all_data['시차변화량2'].replace([np.inf , -np.inf], np.nan).fillna(0)## 신상여부
all_data['신상여부'] = all_data['첫판매월']==all_data['월id']
## 첫판매후 경과기간
all_data['첫판매후기간']=all_data['월id'] - all_data['첫판매월']
#월
all_data['월'] = all_data['월id'] % 12## 필요없는 피처 제거
all_data=all_data.drop(['첫판매월','평균판매가','판매건수','상품명'], axis=1)
all_data=downcast(all_data,False)
## 데이터 분리
#훈련데이터
X_train = all_data.loc[all_data['월id'] < 33]
X_train = X_train.drop(columns = ['월간판매량'], axis=1)
#검증데이터
X_valid = all_data.loc[all_data['월id'] == 33]
X_valid = X_valid.drop(columns = ['월간판매량'], axis=1)
#테스트데이터
X_test = all_data.loc[all_data['월id'] == 34]
X_test = X_test.drop(columns = ['월간판매량'], axis=1)
#타켓값 설정
# 훈련데이터
y_train = all_data.loc[all_data['월id'] < 33 , '월간판매량']
# 판매량값을 0~20으로 제한시킴 <- 이번 경진대회 공지사항에 나와있음
y_train = y_train.clip(0,20)
# 검증데이터
y_valid = all_data.loc[all_data['월id'] == 33 , '월간판매량']
# 판매량값을 0~20으로 제한시킴 <- 이번 경진대회 공지사항에 나와있음
y_valid = y_valid.clip(0,20)
print("훈련데이터" , X_train.shape)
print("검증데이터" , X_valid.shape)
print("테스트" , X_test.shape)
print("타켓_훈련" , y_train.shape)
print("타켓 검증", y_valid.shape)#light gbm 사용하기
import lightgbm as lgb
# 파라미터
params={
'metric' : 'rmse',
'num_leaves': 255,
'learning_rate' : 0.005,
'feature_fraction':0.75,
'bagging_fraction':0.75,
'bagging_freq':5,
'force_col_wise' : True,
'random_state' : 10
}
# 범주형 피처설정
cat_features = ['상점id' , '상품분류id' ,'도시' ,'대분류', '월']
# lightGbm 용 훈련 및 검증 데이터 셋
dtrain = lgb.Dataset(X_train, y_train)
dvalid = lgb.Dataset(X_valid , y_valid)
##모델훈련
lgb_model = lgb.train(
params = params,
train_set = dtrain,
num_boost_round=1500,
valid_sets=(dtrain,dvalid),
early_stopping_rounds=150,
categorical_feature = cat_features,
verbose_eval=100
)## 결과 제출
## 예측 및 결과제출
#예측
preds = lgb_model.predict(X_test).clip(0,20)
#제출파일생성
submission['item_cnt_month']=preds
submission.to_csv('submission.csv',index=False)'Python 데이터분석' 카테고리의 다른 글
| [데이터분석 실습][데이터전처리]구글플레이스토어 데이터 분석 (1) | 2022.07.29 |
|---|---|
| [데이터 분석실습]타이타닉 데이터 (0) | 2022.07.23 |
| [데이터분석실습][이진분류_LR]_Categorical Feature Encoding Challenge (0) | 2022.07.03 |
| [데이터분석실습][회귀_RF/RIDGE/LASSO]자전거 수요예측 (0) | 2022.07.01 |
| [데이터전처리]LabelEncoding / OneHotEncoding (0) | 2022.06.29 |



