
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- FirebaseV9
- ReactNative
- TeachagleMachine
- React
- 머신러닝
- 딥러닝
- expo
- 카트폴
- 클론코딩
- 전국국밥
- 정치인
- 크롤링
- 리액트네이티브
- 강화학습 기초
- redux
- 조코딩
- pandas
- Ros
- App
- kaggle
- 데이터분석
- clone coding
- 앱개발
- 강화학습
- 사이드프로젝트
- coding
- selenium
- python
- Instagrame clone
- JavaScript
Archives
- Today
- Total
qcoding
[데이터분석 실습][데이터전처리]구글플레이스토어 데이터 분석 본문
반응형
## https://www.kaggle.com/datasets/lava18/google-play-store-apps
Google Play Store Apps
Web scraped data of 10k Play Store apps for analysing the Android market.
www.kaggle.com
데이터를 활용하여 데이터 탐색하기
data = pd.read_csv('./googleplaystore.csv')
## 필드명
filed_name = data.columns
print(f"필드명 : {filed_name}")
## 필드갯수
filed_number = len(data.columns)
print(f"필드명 : {filed_number} 개")
## 데이터의 수
data_number = len(data)
print(f"데이터의 수 : {data_number}")## 기본정보확인
## 기본 정보확인
data.info()
## 결측지 확인
data.isna().sum()
# Installs 필드에 'Free'값으로 되어 있는 데이터를 필터
## installs 필드에 'Free'값으로 되어있는 데이터 필터
data_fil=data.copy()
condition_free = data['Installs'] != 'Free'
data_fil= data_fil.loc [condition_free]
data_fil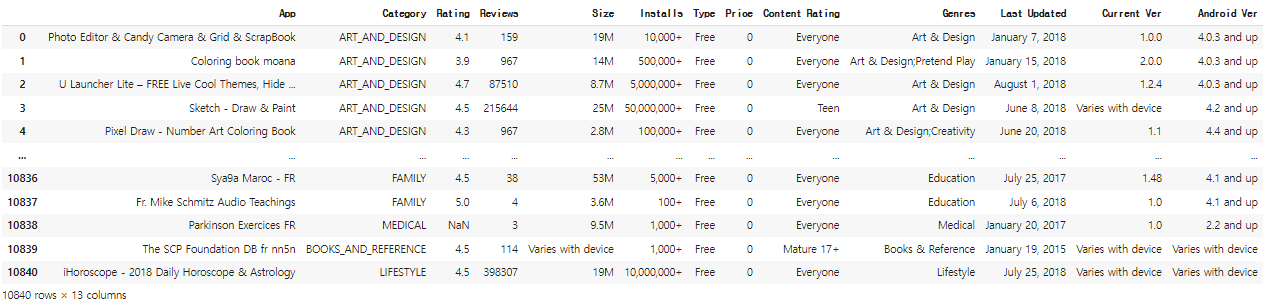
# Installs 필드의 데이터에서 +와 ,를 제거한 후 숫자 타입변경
# "+" 제거
data_fil['Installs']=data_fil.loc[:,'Installs'].apply(lambda x:x[:-1] if "+" in x else x)
# ',' 제거
data_fil['Installs']=data_fil.loc[:,'Installs'].apply(lambda x:x.replace(',',''))
# 숫자 타입으로 변환
data_fil['Installs']=data_fil.loc[:,'Installs'].astype("int")
print(f'data 확인 : ')
{display(data_fil.head(3))}
print(f"type 확인 : {data_fil['Installs'].dtype}")
# Size 필드에 'Varies with device' 값 제거
## size 어떤 값들로 이루어 져있는 지 확인.
## 총 461개의 고윳값으로
## Varies with device 는 총 1695개가 존재함
data_fil['Size'].value_counts()
## size 필드에 'Varies with device'값으로 되어있는 데이터 필터
condition_value = data_fil.loc[:,'Size'] != 'Varies with device'
data_fil = data_fil.loc[condition_value]
## Varies with device가 필터링 된 후 기존 10840 - 1695 = 9145의 데이터 갯수가 남음.
data_fil['Size']
#Reviews 데이터를 숫자로 변경
## 변경전 데이터타입 = 문자열 확인
before_type=data_fil.loc[:,'Reviews'].dtype
print(f'변경전 데이터 타입 : {before_type}')
## 타입변경
data_fil.loc[:,'Reviews'] = data_fil.loc[:,'Reviews'].astype('int')
after_type=data_fil['Reviews'].dtype
print(f'변경후 데이터 타입 : {after_type}')
#Installs가 0 초과인 데이터로 필터 및 Rating, Intalls에서 값이 Nan인 데이터를 제거
## Installs 가 0초과인 데이터로 필터
visual_data = visual_data.loc[visual_data['Installs']>0]
## Rating, Installs에서 값이 Nan인 데이터를 제거함
# Nan 갯수 확인
print(visual_data[['Rating','Installs']].isna().sum())
print(f"Nan제거 전 데이터 총 갯수 : {len(visual_data)}")
# Nan 제거
visual_data=visual_data.dropna(subset=['Rating','Installs'] , axis=0)
# 제거 후 갯수확인
print(f"Nan제거 후 데이터 총 갯수 : {len(visual_data)}")
#X축이 Rating, Y축이 Installs인 점 그래프를 그리고 이 때 Installs의 값이 Rating에 비해 지나치게 크기 때문에 log10로 처리함.
fig , ax = plt.subplots()
fig.set_size_inches(11,5)
plt.scatter(x=visual_data['Rating'] , y=np.log10(visual_data['Installs']) )
plt.title('Rating VS Installs', fontsize=25)
plt.xlabel('Rating', fontsize=20)
plt.ylabel('Installs', fontsize=20)
# X축이 Rating, Y축이 Reviews인 점 그래프를 그리기 이 때, Reviews의 값에 log10을 씌우고, Type으로 GroupBy 하여 Type의 값이 'Free'인 경우는 'red', 'Paid'인 경우는 'green' 으로 표시
## group by 사용
fig , ax = plt.subplots()
fig.set_size_inches(11,5)
group=visual_data.groupby('Type',as_index=False)
color = {'Free' : 'red' , 'Paid' : 'green'}
for label, item in group:
plt.scatter(
x=item['Rating'],
y=np.log10(item['Reviews']),
c=color[label],
label=label
)
plt.title('Rating VS Reviews', fontsize=25)
plt.xlabel('Rating', fontsize=20)
plt.ylabel('Reviews', fontsize=20)
plt.legend()
#Rating, Intalls가 Nan인 데이터는 제거
# Nan 제거
print(f"Nan제거 후 데이터 총 갯수 : {len(analysis_data)}")
analysis_data=analysis_data.dropna(subset=['Rating','Installs'] , axis=0)
# 제거 후 갯수확인
print(f"Nan제거 후 데이터 총 갯수 : {len(analysis_data)}")# Category별 구글 플레이 스토어 점유율을 파이 그래프 그리기
## 고윳값 확인
analysis_data['Category'].nunique()
## 그래프 그리기전에 변수처리
# 점유율 확인
category_percent= (analysis_data['Category'].value_counts() / analysis_data['Category'].value_counts().sum())*100
## 그래프 그리기
fig , ax = plt.subplots()
fig.set_size_inches(11,8)
plt.pie(category_percent, labels=category_percent.index, autopct='%.2f%%',shadow=True)
plt.show()
# 점유율 상위 5개의 카테고리를 구하고, 각각의 Rating 평균, Installs 평균 구하기
## 점유율 상위 5개의 카테고리를 구함
percent_top_5 = category_percent[:5].index
## 상위 5개의 카테고리의 데이터를 필터링
analysis_data_fil=analysis_data.loc[analysis_data['Category'].isin(percent_top_5)]
## 각각의 Rating 평균 / Installs의 평균을 계산함.
group=analysis_data_fil.groupby('Category',as_index=False).agg(
Rating_mean = ('Rating','mean'),
Installs_mean = ('Installs','mean')
).round(2)
group
#점유율 상위 5개의 카테고리중 Rating 평균이 가장 높은 Category를 구하고 해당 Category 데이터를 Type별로 GroupBy한 후 Rating, Installs 평균 구하기
## 점유율 상위 5개의 카테고리중 Rating 평균이 가장 높은 Category 확인
## Game이 제일 높은 카테고리
group.sort_values('Rating_mean' , ascending=False)
## Game 카테고리 데이터를 Type 별로 Group By 수행하고 Rating과 평균을 계산함
group_game=analysis_data.loc[analysis_data['Category']=='GAME'].groupby('Type',as_index=False).agg(
Rating_mean = ('Rating','mean'),
Installs_mean = ('Installs','mean')
).round(2)
group_game
반응형
'Python 데이터분석' 카테고리의 다른 글
| [데이터분석실습][이진분류_LR/XGB]Heart Failure Prediction_kaggle (0) | 2022.08.13 |
|---|---|
| [데이터분석실습][데이터전처리]스타벅스 고객 데이터 분석하기 (0) | 2022.08.06 |
| [데이터 분석실습]타이타닉 데이터 (0) | 2022.07.23 |
| [데이터분석실습][회귀-LGBM/XGB] 향후 판매량 예측 _ 회귀 (0) | 2022.07.12 |
| [데이터분석실습][이진분류_LR]_Categorical Feature Encoding Challenge (0) | 2022.07.03 |
'Python 데이터분석' Related Articles
more




Comments