
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 카트폴
- 전국국밥
- pandas
- 조코딩
- clone coding
- 사이드프로젝트
- 머신러닝
- coding
- 리액트네이티브
- 앱개발
- 크롤링
- Ros
- React
- expo
- ReactNative
- 정치인
- JavaScript
- 강화학습 기초
- App
- 딥러닝
- selenium
- 클론코딩
- redux
- 데이터분석
- Instagrame clone
- 강화학습
- FirebaseV9
- kaggle
- TeachagleMachine
- python
- Today
- Total
qcoding
[강화학습]Dqn_Mountain car_강화학습 예제 본문
https://gymnasium.farama.org/environments/classic_control/mountain_car/
Gymnasium Documentation
A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
gymnasium.farama.org
* 이번 실습은 Mountain car로 openai_gym이 제공하는 환경 중 카트폴과 비슷하게 classic 문제로 대표적인 예라고 볼 수 있다.
대부분의 내용은 이전 글과 동일하므로 이전 내용을 참고하면 되며, 여기서는 보상을 어떤식으로 설계를 하였는 지에 대해서 세세하게 살펴볼 예정이다.
2023.01.14 - [머신러닝 딥러닝] - [강화학습]Cartpole(카트폴) Deep Q-learning (Dqn) 실습
[강화학습]Cartpole(카트폴) Deep Q-learning (Dqn) 실습
[Deep Q-learning] * 이번실습은 강화학습 실습으로 유명한 Carpole 을 deep q-learning으로 구현해보는 실습을 진행하였다. DQN은 미래에 받을 가치와 현재 가치의 차이를 줄이면 현재의 가치를 최적의 상태
qcoding.tistory.com
글의 내용은 아래와 같이 진행됩니다. 해당 학습을 진행하면서 다른 분들이 쓴 글들을 참조하였습니다.
*참고 글 :
https://davinci-ai.tistory.com/33 ,
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sonmh12&logNo=222036705425
1) Mountain_car 소개
2) 전체 코드 내용
* 보상 설계 부분 중심으로 정리
3) 강화학습 결과
1) Mountain_car 소개
우선 Mountain_car 문제에 대해서 확인해보도록 하자. open_ai 공식 홈페이지를 살펴보면 아래와 같이 해당 문제에 대한 정보가 나온다.

1-1) Observation Space (= state)
-> 우선 state를 살펴보면 shape은 2로 총 2가지의 정보를 담고 있다. ( x방향으로의 위치 , 차량의 속도) 의 정보를 받으며, Min/ Max 값은 아래와 같은 것을 확인할 수 있다.

1-2) Action Space
-> agent가 할 수 있는 action을 살펴보면 총 3가지의 action이 있으며, 0: 왼쪽으로 accel / 1: accel 미동작 / 2: 오른쪽으로 accel로 적절한 state (위치 , 속도) 정보를 보고 그에 맞는 action을 수행해 주어야 문제를 해결할 수 있다.

1-3) 에피소드 종료 조건
-> 종료조건을 살펴보면 아래와 같다. 에피소드가 해결이 되는 것은 Temination으로 자동차의 위치가 0.5m 이상이 되어야 되며, 즉 언덕을 넘어가서 goal에 도달하는 것이며, Truncation은 에피소드가 너무 길어지기 때문에 문제를 종료시키는 것으로 총 200 타임스템을 넘어가면 종료를 시킨다.
- Termination: 자동차의 위치가 0.5보다 크거나 같습니다(오른쪽 언덕 위의 목표 위치).
- Truncation: 에피소드 길이는 200입니다.
1-4) Reward (환경이 agent에 주는 값)
-> 목표는 가능한 한 빨리 오른쪽 언덕 위에 놓인 깃발에 도달하는 것이므로 에이전트는 각 타임스텝에 대해 -1의 보상으로 페널티를 받는다. 즉 -1씩 증가할 때, 위의 에피소드 종료조건인 200 타임스텝을 지나면 -200 reward를 받고 에피소드가 종료되게 된다. 만약 200 타임스텝을 되기 전에 에피소드를 성공했다면 -200 보다 높은 rewrad 값으로 에피소드를 마감할 것이다. ex) 194 step만에 성공 -> reward : -194 // 200step 동안 성공못함 -> reward : -200
위의 내용을 그림으로 정리하면 아래와 같다. ( 참고한 블로그에서 좋은 그림이 있어서 가져왔다. )

기본적으로 오른쪽 방향으로 accel을 하더라도 동력이 부족하여 보상지점에 도달하지 못한다. 따라서 오른쪽 언덕에서 내려올 때 반대방향으로 가속을 해서 추진력을 얻어야 이 문제를 해결할 수 있다.
2) 전체코드
colab을 기준으로 작성하였습니다.
* 필요한 라이브러리 설치
!sudo apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb \
xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
!pip install pyvirtualdisplay
!pip install piglet
* gym 환경 설치
## gym
!pip install gym[classic_control]
##ffmpeg
!sudo apt-get install ffmpeg -y* 동영상으로 재생할 수있게 만들어주는 함수 작성
### import
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1400, 900))
display.start()
from base64 import b64encode
from glob import glob
from IPython.display import HTML
from IPython import display as ipy_display
from gym import logger as gym_logger
from gym.wrappers.record_video import RecordVideo#### show video func
def show_video(mode='train', filename=None):
mp4_list = glob(mode+'/*.mp4')
# print(mp4_list)
if mp4_list:
if filename :
file_lists = glob(mode+'/'+filename)
if not file_lists:
print('No {} found'.format(filename))
return -1
mp4 = file_lists[0]
else:
mp4 = sorted(mp4_list)[-1]
print(mp4)
video = open(mp4, 'r+b').read()
encoded = b64encode(video)
ipy_display.display(HTML(data='''
<video alt="gameplay" autoplay controls style="height: 400px;">
<source src="data:video/mp4;base64,%s" type="video/mp4" />
</video>
''' % (encoded.decode('ascii'))))
else:
print('No video found')
return -1
* 필요 라이브러리 import
import tensorflow as tf
from tensorflow import keras
from collections import deque
import numpy as np
import random
import gym
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import os
import warnings
warnings.filterwarnings(action='ignore')* Early stopping을 위한 Class
#### early stopping by avg
class EarlyStopping_by_avg():
def __init__(self, patience=10, verbose=0):
super().__init__()
self.best_avg = 0
self.step = 0
self.patience = patience
self.verbose = verbose
def check(self, avg , avg_scores):
## best avg가 나올경우
if avg >= self.best_avg:
self.best_avg = avg
self.step = 0
# print("avg_reset")
## 이전값보다 현재 avg가 높을경우
elif len(avg_scores) > 1 and avg > avg_scores[-2]: ### 이전 값과 비교해야하므로 -2 , -1은 지금 avg와 동일함
self.step = 0
# print("이전값보다 avg 높아서 reset")
else:
self.step += 1
if self.step > self.patience:
if self.verbose:
print('조기 종료')
return True
return False
* Agent (DQN) 코드
class DQN():
def __init__(self, state_size, action_size):
## 상태 및 행동 size 정의
## stae = 2가지 정보 , action = 3가지 정보
self.state_size = state_size
self.action_size = action_size
## 감쇠율 / 엡실론 정의
## GLIE (Greedy in the limit of infinite exploration)
self.gamma = 0.99
self.epsilon = 1.0
self.epsilon_decay = 0.999
self.epsilon_min = 0.01
## 리플레이 버퍼 크기 / 시작 size
self.buffer_size = 5000
self.buffer_train_start = 1000
## 리플레이 버퍼 정의
self.buffer = deque(maxlen=self.buffer_size)
## 인공신경망 학습 파라미터
self.loss_fn = keras.losses.MeanSquaredError()
self.learning_rate = 0.001
self.optimizer = keras.optimizers.Adam(learning_rate = self.learning_rate)
self.batch_size = 32
## network 정의
## q-network
self.q_network = self.get_network()
## target q-network
self.target_q_network = self.get_network()
## target q-network weight update
self.update_target_network()
### check point 생성
self.dir_name = os.getcwd()
self.folder_checkpoint = os.path.join(self.dir_name,f'checkpoint_{ENV_NAME}')
self.checkpoint = tf.train.Checkpoint(model=self.q_network , optimizer=self.optimizer)
self.manager = tf.train.CheckpointManager(self.checkpoint, self.folder_checkpoint, max_to_keep=40)
### q-network 생성
def get_network(self):
### state가 들어감
input_ = keras.layers.Input(shape=(self.state_size))
x = keras.layers.Dense(128, activation='relu')(input_)
x = keras.layers.Dense(128, activation='relu')(x)
x = keras.layers.Dense(24, activation='relu')(x)
# x = keras.layers.Dense(12, activation='relu')(x)
## output은 행동가치함수 이므로 행동(=action)의 수와 동일하게 생성
output = keras.layers.Dense(self.action_size, activation='relu')(x)
model = keras.models.Model(inputs=[input_], outputs=[output])
return model
### target q-network 가중치 업데이트
def update_target_network(self):
## q-network에서 weights를 가져와서 target q network에 weights를 업데이트 함.
weights = self.q_network.get_weights()
self.target_q_network.set_weights(weights)
### 리플레이 버퍼에 저장
def memory_buffer(self, state, action, reward, next_state, done):
### 리플레이 버퍼에 저장함
item = (state, action, reward, next_state, done)
self.buffer.append(item)
### 정책 결정 - 엡실론 greedy
### state 를 입력으로 받고 action을 결정
def policy(self, state):
## 균등분포로 부터 무작위 표본 추출 np.random.uniform(low, high, size)
## 0 ~ 1사이의 균등분포에서 난수를 생성함
## exploration - 탐험 ( 무작위 적으로 action을 생성함)
## 처음에는 epsilon이 크니깐 작을 확률이 큼 -> 시간이 갈수록 epsilon이 작아짐
if np.random.uniform(0,1) < self.epsilon:
### 총 3가지의 action 사이즈를 가진 list [0,1,2] 에서 랜덤으로 한개를 선택함
### action = 0 : accel to left , 1: don't accel , 2: accel to right
action = np.random.choice([x for x in range(self.action_size)])
## greedy 적용
## q-network를 사용하여 나오는 행동가치함수 (q) [[0.2,0.5, 0.1], [0.5, 0.7 , 0.6] ... ] -- action이 3가지이므로 3가지 값이 나옴
else:
out = self.q_network(state)
# out = [Q[0], Q[1]]
### output로 나오는 행동가치 q(state_t, acion_t | theta ) 중 큰 액션을 선택함 [[0.2,0.5, 0.1], [0.5, 0.7 , 0.6] ... ]
action = np.argmax(out)
return action
### 학습과정
def train(self):
### 엡실론 greedy (GLIE) 구현 -> 학습이 반복될 수록 epsilon값이 작아지게 함
self.epsilon = max(self.epsilon_min, self.epsilon * self.epsilon_decay)
### 리플레이 buffer에서 batch_size 만큼 랜덤하게 추출하여 mini_batch 구현함
### random.sample(sequence, k) , sequence 에서 k개를 추출함
### buffer에서 batch_size 만큼을 추출함
### buffer 자료구조
### item = (state, action, reward, next_state, done)
### self.buffer.append(item
# [
# (state, action, reward, next_state, done | t일때),
# (state, action, reward, next_state, done | t+1일때),
# ... deque의 구조로 계속 추가 됨
# ]
mini_batch = random.sample(self.buffer , self.batch_size)
### mini_batch에서 각 정보로 분리하기
## zip(*mini_batch) --> zip안에 *을 붙이면 열(column) 방향으로 각각 분리됨
## ex) [ (state | t일때 , state | t+1일때 ...) ,
## (action |t일때 , action | t+1일때) ... ,
## 나머지 reward , next_state, done 등 동일
## ]
states, actions, rewards, next_states, dones = zip(*mini_batch)
# 분리된 정보를 tensor 형태로 변환
states = tf.convert_to_tensor(states)
actions = tf.convert_to_tensor(actions)
rewards = tf.convert_to_tensor(rewards)
next_states = tf.convert_to_tensor(next_states)
# dones를 True False로 바꿀 껀데 tf.float32 실수 형태로 바꿔 주는코드 (1.0 , 0.0)
dones = tf.convert_to_tensor(dones, dtype=tf.float32)
### 학습Target 정의
## r + gamma * max_q_target(next_s)
# mini_batch 단위로 elements-wise하게 계산되어야 합니다
# 에피소드의 마지막 상태의 경우, only 보상이 target 값이 된다. --> 여기서 뜻하는 것은 에피소드가 끝나면 받을 가치는 위의식에서 r 만 남음
# ( 앞으로의 state 다음이 없으므로 gaama * max_q_target이 없음)
################### target_q_network ########################
### 미래에 대한 target을 정하는 부분 --> 미래에 받을 가치와 현재가치를 갖게 하면 현재의 가치를 최적의 상태로 만들 수 있음
q_next = self.target_q_network(next_states) ## 미래에 받은 행동가치함수(q)값
## 축별로 큰값을가져옴
# np.amax([
# [0.1, 0.9, 0.8] --> 각 행동가치함수(q)값에서 가장 큰 값을 가져와야함. 여기서는 0.9
# ,[0.7, 0.3, 0.4]
# ], axis=1) 만일 axis=0 이면 array([0.7, 0.9]) / axis=1이면 array([0.9, 0.7]) 로 각축별로 가져와야함으로 axis=1이됨
### 식 r_t+1 + gamma * max_q(state_t+1, acion_t | theta )
max_q_next = np.amax(q_next , axis=-1) ### 여기서 q_next값이 2차원이므로 axis=1 이나 axis=-1이나 열방향을 의미함
## 에피소드 끝나지 않았을 경우 (done = False)
## 에피소드 끝났을 경우 (done = True) 의 경우 self.gamma * max_q_next 값을 포함하지 않아야함.
targets = rewards + ( self.gamma * max_q_next ) * ( 1-dones )
################### q_network ########################
### 현재에 대한 행동가치를 정하는 부분
## tf.GradientTape 함수 참조 : gradienttape : https://devbruce.github.io/machinelearning/ml-11-tf_gradienttape/
with tf.GradientTape() as tape:
## 현재 action에 대한 행동가치(q) 값을 구한다.
q = self.q_network(states)
## 현재 수행하는 action을 가지고 위의 행동가치(q)와 곱해주기 위해서 차원을 맞춰준다.
## ex) q= np.array([[0.1, 0.9,0.8],[0.7, 0.3,0.4]])
## actions = np.array([1 , 2]
## 위의 두개의 곱으로 q_sa 를 계산하기 위하여 , 즉 행동가치(q)를 계산하기 위하여 현재 취했던 action을 나타내기 위해 one-hot encoding수행
## one_hot_a = tf.one_hot( actions, 3 )
## [[0. 1. 0.]
## [0. 0. 1.]]
## q_sa = tf.reduce_sum(q * one_hot_a, axis=1) 을 수행 시
## tf.Tensor([0.9 0.4], shape=(2,), dtype=float32) 이 나온다. 즉 축을 합치면서 axis=1 (열 방향)으로 더해준다.
### 현재 action
one_hot_a = tf.one_hot(actions , self.action_size)
## q_sa -> 현재 수행한 action의 가치값(q)을 계산함. --> 위의 target은 미래 state를 target q-network에 넣고 action에 관계없이 가장 가치가 큰 값을 가져옴
q_sa = tf.reduce_sum(q * one_hot_a, axis=1)
# 오차 계산 --> 미래가치와 현재가치의 차이를 오차로 계산함
loss = self.loss_fn(targets, q_sa)
# 손실함수를 통해 계산한 오차를 네트워크 가중치로 미분!
## 여기서 q_network 만 학습을 진행함
### 아래코드의 의미는 loss에 대한 각 self.q_network.trainable_weights 파라미터의 gradient를 계산하여 grads로 설정함
grads = tape.gradient(loss, self.q_network.trainable_weights)
# 미분값을 기준으로 각 네트워크 가중치를 업데이트!
### zip으로 묶는 것은 각 grads에 맞게 update가 필요함. ( grads[0] , trainable_weights[0] ) , (grads[1] , trainable_weights[1])
self.optimizer.apply_gradients(zip(grads, self.q_network.trainable_weights))
### check point 저장하기
save_path = self.manager.save()
# print("Saved checkpoint {}".format(save_path))
* Env (환경)
#### 학습 환경
# CartPole 환경 정의
ENV_NAME = 'MountainCar-v0'
# env = gym.make(ENV_NAME, render_mode="rgb_array")
env = gym.make(ENV_NAME)
# 비디오 레코딩
env = RecordVideo(env, './train', episode_trigger =lambda episode_number: True )
env.metadata = {'render.modes': ['human', 'ansi']}
# CartPole 환경의 상태와 행동 크기 정의
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# 위에서 정의한 DQN 클래스를 활용하여 agent 정의
agent = DQN(state_size, action_size)
scores, avg_scores, episodes ,avg_rewards = [], [], [], []
# 반복 학습 에피소드 수 정의
num_episode = 100
early_stopping_by_avg = EarlyStopping_by_avg(patience=2, verbose=1)
## early stopping을 위한 초기값 설정
avg_reward_episode = 0
success = 0
max_position = -0.4
for epoch in range(num_episode):
# done flag와 score 값 초기화
done = False
score = 0
step = 0
rewards_list = []
# 환경 reset을 통해 초기 상태 정의 --> state는 [car_position , car_velocity] 2개의 값을 받는데
# car_position = -0.6 ~ 0.4 사이의 값을 받으며 , car_velocity = 0 을 받음
state = env.reset()
# print(f'init_state : {state}')
# print(f"avg: {avg_step}")
if early_stopping_by_avg.check(avg_reward_episode , avg_scores ):
print("earstpping 실행")
break
while not done:
# 현재 상태에 대하여 행동 정의
# action = agent.policy(init_state[np.newaxis,:]) ### network에 넣어 주기 위해서 기존 (2,) 배열을 (1,2)로 축을 추가함
action = agent.policy(np.expand_dims(state, axis=0))
### 위와 같은 의미 np.expand_dims(a, axis=0)
# env.step 함수를 이용하여 행동에 대한 다음 상태, 보상, done flag 등 획득
### return ex) nex_state=[-0.57330334 -0.00063329]
### reward=-1.0
### done=False
### info={}
next_state, reward, done, info = env.step(action)
### reward 설계
#### 목표는 가능한 한 빨리 오른쪽 언덕 위에 놓인 깃발에 도달하는 것이므로 에이전트는 각 타임스텝에 대해 -1의 보상으로 페널티를 받습니다.
#### 다음 중 하나가 발생하면 에피소드가 종료됩니다.
###종료: 자동차의 위치가 0.5보다 크거나 같습니다(오른쪽 언덕 위의 목표 위치).
###잘림: 에피소드 길이는 200입니다.
### reward 설계
#### 목표는 가능한 한 빨리 오른쪽 언덕 위에 놓인 깃발에 도달하는 것이므로 에이전트는 각 타임스텝에 대해 -1의 보상으로 페널티를 받습니다.
#### 다음 중 하나가 발생하면 에피소드가 종료됩니다.
###종료: 자동차의 위치가 0.5보다 크거나 같습니다(오른쪽 언덕 위의 목표 위치).
###잘림: 에피소드 길이는 200입니다.
# reward=0.1 if not done else -1
### position에 따라서 action이 맞으면 reward를 줌
car_pos = next_state[0]
car_vel = next_state[1]
##### 여기서는 pos가 reward 임
if car_vel > 0:
reward = float(((car_pos+0.5)*20)**2/10+15*car_vel-step/400)
else:
reward = float(((car_pos+0.5)*20)**2/10 - step/400)
### max position
if car_pos > max_position:
## max position
max_position = car_pos
## 성공 시 success
if car_pos >= 0.5:
success +=1
reward = 20
else:
score -= 1
# 해당 에피소드의 최종 score를 위해 reward 값 누적
step += 1
# print(f'reward : {reward}')
# 획득된 상태, 행동, 보상, 다음상태, done flag를 리플레이 버퍼에 축적
rewards_list.append(reward)
agent.memory_buffer(state, action, reward, next_state, done)
# 다음 상태를 현재 상태로 정의
state = next_state
# buffer 크기가 일정 기준 이상 쌓이면 학습 진행
# TODO #
if len(agent.buffer) >= agent.buffer_train_start :
agent.train()
if done:
### early stop
avg_score_episode = np.mean(scores[-10:])
avg_reward_episode = np.mean(rewards_list)
# 에피소드가 종료되면 target_q_network 파라미터 복제
# TODO #
agent.update_target_network()
# 에피소드 종료마다 결과 그래프 저장
#### reward --> 매 스텝에서 받은 reward의 양 ( state에서 알맞는 action을 많이 할 수록 reward가 커짐)
avg_rewards.append(avg_reward_episode)
#### score --> 환경에서 reward는 매 step마다 -1 감소 인데, 200 step이 되면 종료되므로, -200 보다 커질수록 높은 score
scores.append(score)
avg_scores.append(avg_score_episode)
episodes.append(epoch)
# 에피소드 종료마다 결과 출력
print(f'episode: {epoch:3d} | success: {success} | car_pos_max : {max_position : .3f} | avg_reward : {avg_reward_episode : .3f} | score_avg : {avg_score_episode : .3f} | step : {step} | buffer_size: {len(agent.buffer):4d} | epsilon: {agent.epsilon:.4f}')
env.close()
plt.title('Test graph')
plt.xlabel('episodes')
plt.plot(episodes, avg_scores,
color='skyblue',
marker='o', markerfacecolor='blue',
markersize=6)
plt.ylabel('avg_scores', color='blue')
plt.tick_params(axis='y', labelcolor='blue')
plt.savefig('cartpole_graph.png')
plt.show()기본적으로 이전의 Carpole과 동일하게 구성되어 있으므로 별다른 내용은 없다. 단지 내용이 조금 달리진 부분은 action size와 state size 이며, 해당 환경에서는 action이 3가지 중에 한가지 즉, 왼쪽 / 오른쪽/ 정지 중 한가지의 action을 나타내므로 앞의 문제와 동일하다.
( * 만약 state를 입력받고, action을 내보내는 뉴럴넷에서 action이 [핸들 , 가속 , 브레이크] 와 같이 3가지 vector 형태로 이루어 진다면 코드를 수정해야 하지만 지금의 문제는 0 / 1 / 2 와 같이 단일 idx를 같게 나오기 때문에 carpole문제와 동일하게 사용한다.https://gymnasium.farama.org/environments/box2d/ 이 문제처럼 vector로 존해할 경우 다르게 표현)
* 보상설계
-> 이 문제를 처음 풀면서 보상설계를 제대로 하지 않았을 경우 아무리 해도 문제가 풀리지 않았다. 답답해 하고 있는 와중에 위의 참고한 블로그 중 2번째를 참고하여 보상설계를 진행하였고, 매우 좋은 결과를 얻었다. 블로그에서 작성한 보상설계를 나눠보면 크게 아래와 같다.
보상설계 1) 이차 함수 형태로 보상을 정의
### position에 따라서 action이 맞으면 reward를 줌
car_pos = next_state[0]
car_vel = next_state[1]
##### 여기서는 pos가 reward 임
if car_vel > 0:
reward = float(((car_pos+0.5)*20)**2/10+15*car_vel-step/400)
else:
reward = float(((car_pos+0.5)*20)**2/10 - step/400)
-> 위에서 설명한 것처럼 오른쪽으로 갈수록 더 많은 보상을 위해 차량속도에 따라 보상을 다르게 설정하며, 2차함수로 근사하여 차량 위치에 따라 보상을 다르게 하였다. 위와 같이 하면 학습이 잘 이루어지는 것을 확인할 수 있다. 여기에서 사용한 a,b,c,d의 값들은 사용자가 임의로 설정하여 사용하면 될 것 같다.
보상설계 2) 이차 함수 형태로 보상을 정의
## 성공 시 success
if car_pos >= 0.5:
success +=1
reward = 20
else:
score -= 1-> 성공을 하게 되면 reward = +20 이라는 큰 보상을 받게 되며, 그 외에는 위의 환경에서 정의하는 -1의 score를 받는다.
보상설계는 아니지만 학습이 잘되는 지 확인하기 위해 max_position을 설정함
## 초기에 에피소드 position을 설정하고 에피소드 수행
max_position = -0.4
while not done:
### max position
if car_pos > max_position:
## max position
max_position = car_pos학습이 진행될 때 대략 차량의 위치가 0.5m 라는 goal에 가까이 가고 있는 지 확인하기 위해서 위의 max_position 변수를 설정하였다. 즉 에피소드가 시작되면서 max_position 값이 점점 (+)로 가면서 0.5m로 가까워 지면 학습이 잘이루어지고 있다는 것을 뜻한다.
3) 강화학습 결과

학습의 결과를 살펴보면, 22번 에피소드 부터 car_pos_max값이 0.5m 넘어서 성공하는 것을 볼 수 있다. 또한 car_pos_max 값이 계속해서 증가하고 있으므로 학습이 잘 이루어 지고 있음을 확인 할 수 있다.
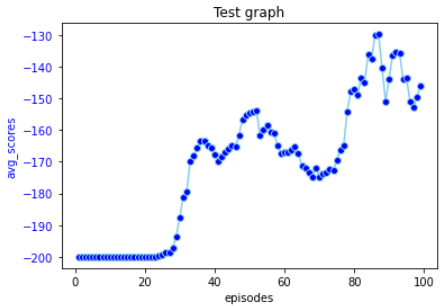
100 에피소드를 수행한 결과 위와 같은 결과를 얻으며, 여기서 y축은 -200 보다 커질 수록 더 적은 step만에 문제를 해결한 것을 의미한다. abs( -200 - y축 값) 이 문제를 몇번의 time step 만에 성공했는 지에 대한 그래프이다.
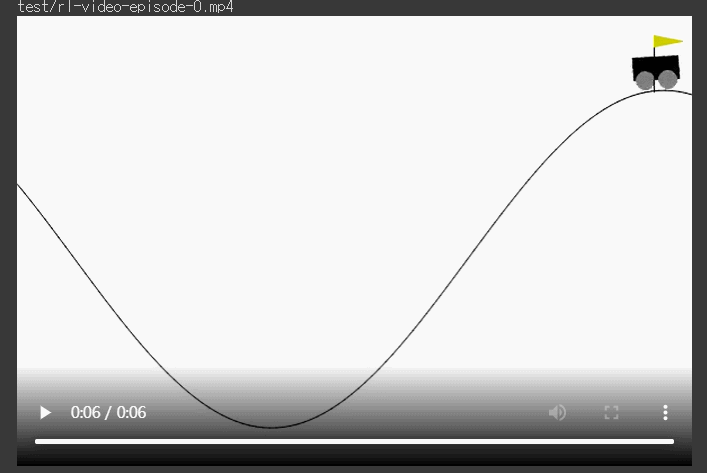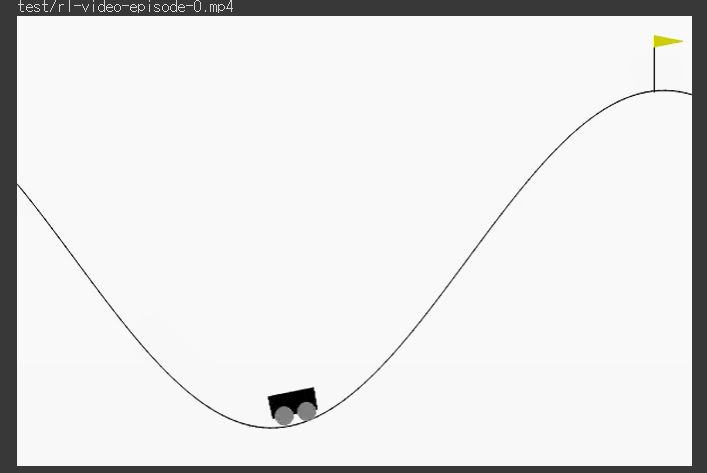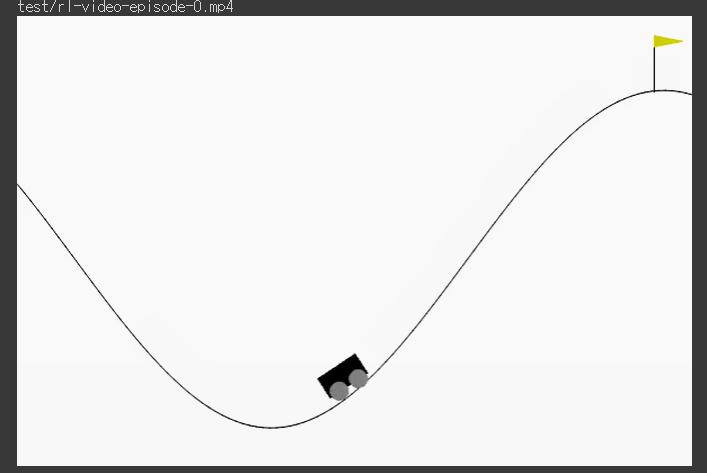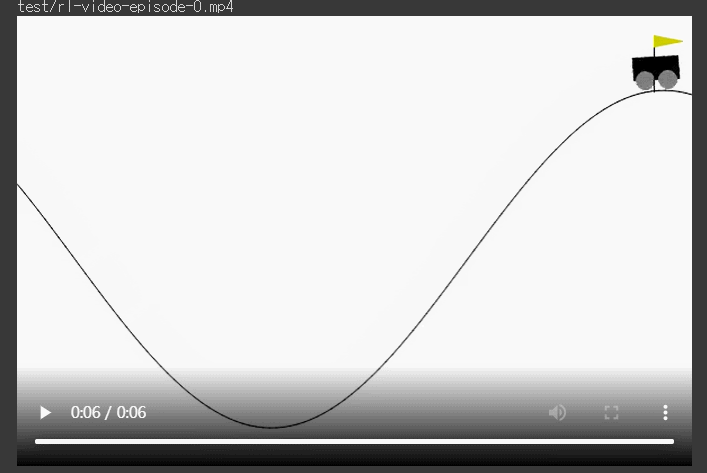
가장 높은 score를 갖는 에피소드를 재생하면 아래와 같다.
### max episode
### nan이 젤 큰값이므로 이값을제거하고 계산함
avg_scores_fil = [x for x in avg_scores if np.isnan(x) !=True]
episode=np.argmax(avg_scores_fil)
# episode=88
filename = 'rl-video-episode-{}.mp4'.format(episode)
# print("최대 avg : {} ,에피소드 번호 : {}".format(max(avg_scores_fil) , episode))
show_video(filename=filename)*** 학습이 안됐을 때
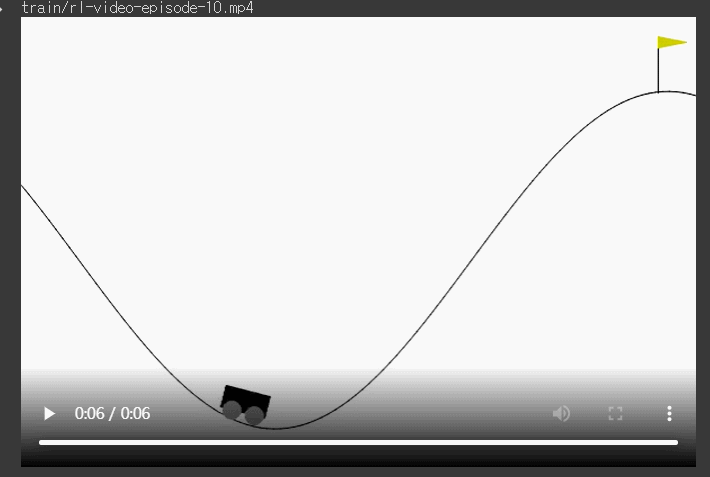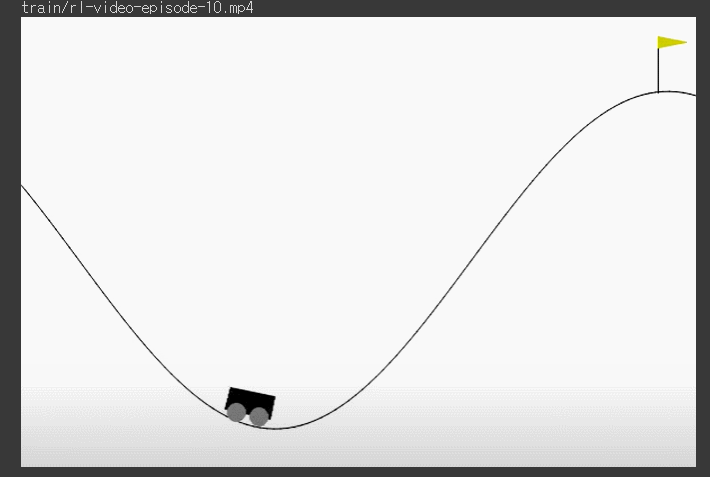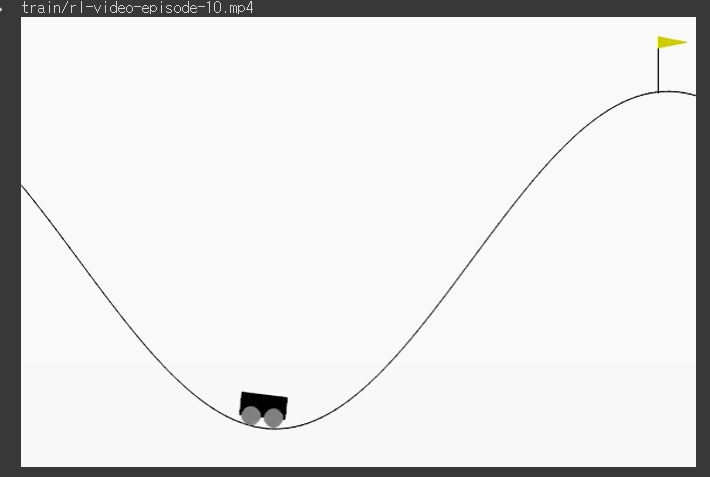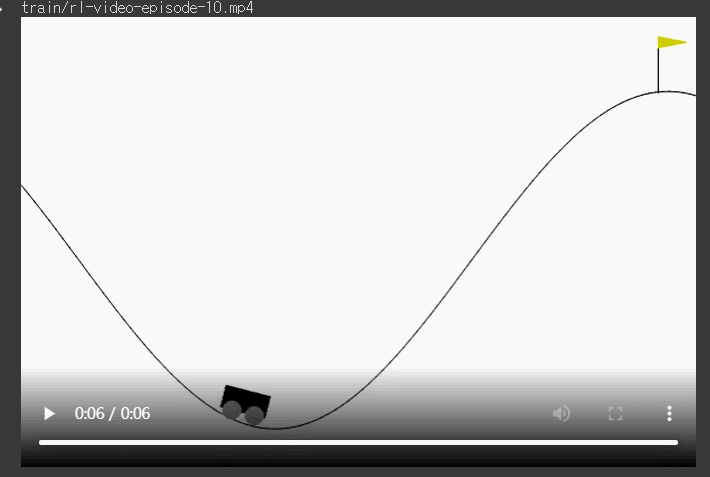
*** 학습이 잘 됐을 때
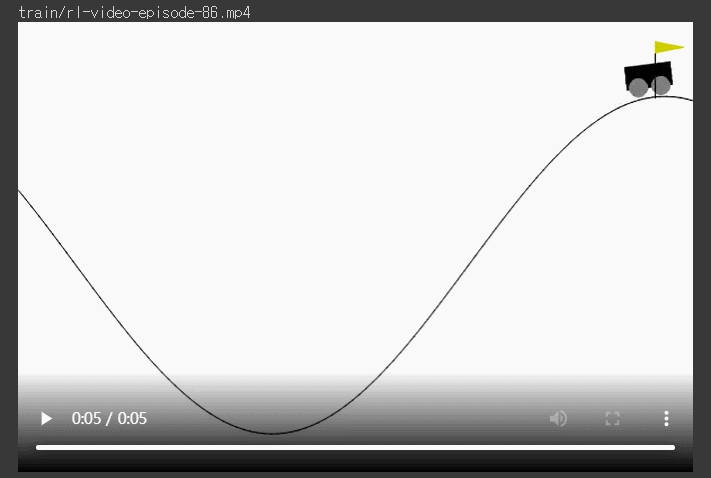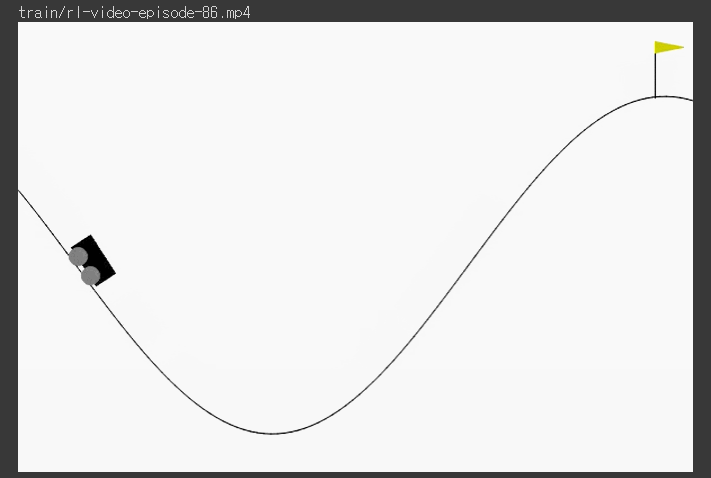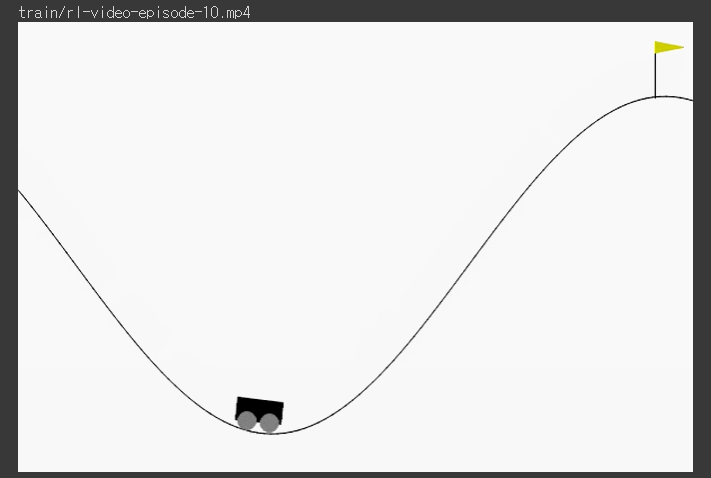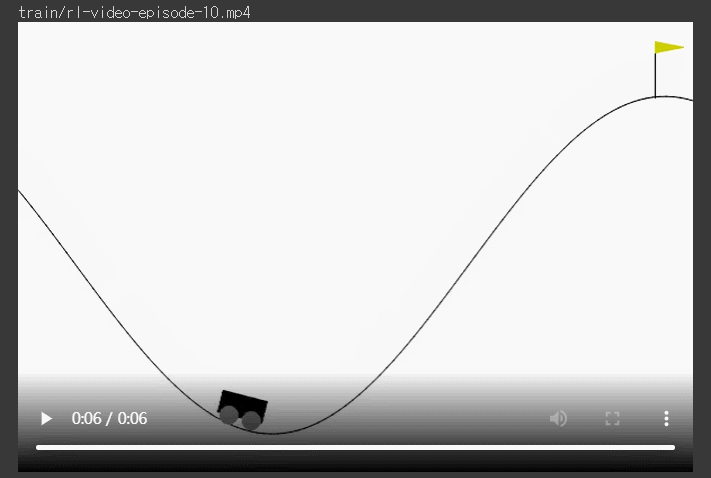
*** 저장된 check point로 불러와서 test 진행
tf.random.set_seed(42)
# MountainCar 환경 정의
ENV_NAME = 'MountainCar-v0'
env = gym.make(ENV_NAME)
# 비디오 레코딩
env = RecordVideo(env, './test', episode_trigger = lambda episode_number: True)
# greedy policy
agent.epsilon = 0.0
score = 0
state = env.reset()
done = False
#### 저장된 가중치 load
idx = 1
weights = agent.manager.checkpoints[idx]
print(weights)
# last_weights=tf.train.latest_checkpoint(agent.folder_checkpoint)
# last_weights = agent.manager.latest_checkpoint
# print(weights)
agent.checkpoint.restore(weights)
# agent.checkpoint.restore(weights)
weights_list = agent.q_network.get_weights()
# print(weights_list[0][0])
# print(f'init state : {state}')
# print(weights)
# if weights:
# print("Restored from {}".format(weights))
# else:
# print("Initializing from scratch.")
car_pos = []
step = 0
rewards = 0
while not done:
# 현재 상태에 대하여 행동 정의
action = agent.policy(state[np.newaxis,:])
# print(f'init action : {action}')
# env.step 함수를 이용하여 행동에 대한 다음 상태, 보상, done flag 등 획득
next_state, reward, done, info = env.step(action)
# 해당 에피소드의 최종 score를 위해 reward 값 누적
if done:
print(f"Score: {score} , Step : {step} , Car_pos : {np.max(car_pos) : .3f} , Rewards : {rewards}")
break
score += -1
rewards += reward
step += 1
car_pos.append(next_state[0])
# 다음 상태를 현재 상태로 정의
state = next_state
### 동영상 재생
### video
show_video(mode='test')
'머신러닝 딥러닝' 카테고리의 다른 글
| [강화학습]A2C (Actor-Critic)CartPole_Mountain Car 문제 (0) | 2023.02.11 |
|---|---|
| [강화학습]정책기반 강화학습_Policy Gradient_Reinforce_Cartpole (0) | 2023.02.05 |
| [강화학습]Cartpole(카트폴) Deep Q-learning (Dqn) 실습 (0) | 2023.01.14 |
| [CNN]CAM (Class Activation Map) (1) | 2023.01.06 |
| [CNN 피처추출] 거리기반 유사 이미지 추천하기 (Flow Recognition data) (1) | 2022.12.27 |



