
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- clone coding
- 클론코딩
- pandas
- expo
- 강화학습
- GYM
- coding
- 데이터분석
- Ros
- ReactNative
- 카트폴
- 리액트네이티브
- TeachagleMachine
- 조코딩
- 사이드프로젝트
- 딥러닝
- FirebaseV9
- 전국국밥
- selenium
- kaggle
- 앱개발
- 머신러닝
- redux
- Reinforcement Learning
- React
- App
- 강화학습 기초
- Instagrame clone
- JavaScript
- python
- Today
- Total
qcoding
[VGG16 전이학습] 강아지 고양이 분류 본문
https://www.kaggle.com/datasets/tongpython/cat-and-dog
Cat and Dog
Cats and Dogs dataset to train a DL model
www.kaggle.com
## 이미지 분류의 대표적인 강아지 / 고양이 분류 문제를 VGG16의 전이학습을 통해서 구현해보는 실습을 진행하려고 한다.
진행순서는 아래와 같으며, kaggle 데이터 set을 활용하며, google drive와 colab을 사용하여 실습예정이다.
1) 데이터 set 다운로드 후 google drive upload --> colab에서 구글드라이브 연동 후 불러오기
2) 전체 이미지를 numpy array로 만들기
3) 이미지 시각화
4) 이미지 전처리 ( scaling / Augmentation)후 데이터 분리 (학습 / 검증)
5) 모델 만들기
6) 모델 학습 및 결과 확인
1) 데이터 set 다운로드 후 google drive upload --> colab에서 구글드라이브 연동 후 불러오기
-> 위의 kaggle 사이트로 접속 후 data set을 다운받는다. 다운 받으면 archive.zip 란 이름으로 파일이 생기게 되는데 이를 구글 드라이브에 업로드를 시킨 후 드라이브를 연동시킨다.
from google.colab import drive
drive.mount('/content/drive')그 다음 구글드라이브에서 실습을 진행할 폴더를 만든 뒤 위의 업로드 한 압축파일을 풀어준다.
import time
import os
## 실습을 진행할 폴더를 설정함
foler_path ='/content/drive/MyDrive/Project/cat_and_dog'
## 아래의 코드는 위의 폴더가 없을 시 폴더를 생성하고 chdir을 통해서 만들어진 폴더경로로 이동 후
## dataset 이라는 하위 폴더를 만드는 코드이다
## 위의 코드대로 실행하면 /content/drive/MyDrive/Project/cat_and_dog/dataset 으로 현재 폴더위치가
## 이동될 것이다.
try:
os.makedirs(foler_path)
except:
pass
os.chdir(foler_path)
try:
os.makedirs('dataset')
except:
pass그 다음 압축해제를 실행한다.
# # 구글 드라이브에 압축 해제
ts = time.time()
### 앞의 경로는 압축파일이 있는 경로 이며, 위의 './dataset'의 경우는 현재 지정되어 있는 경로이다.
## 현재 지정경로 /content/drive/MyDrive/Project/cat_and_dog/dataset
!unzip -q '/content/drive/MyDrive/Data_set/archive.zip' -d './dataset'
te = time.time()
print("time : ", int((te - ts) / 60), " min.")
약 4분정도의 시간이 지난 뒤 압축이 풀린 것을 확인할 수 있다.
파일 구조를 보면 아래와 같은 형태가 되는 것을 확인할 수 있다.
## linux tree 사용하지 않고 파일구조 확인
ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'
2) 전체 이미지를 numpy array로 만들기
--> 다음으로 이미지 파일들을 전체 배열로 만들어 train / valid set으로 나눠서 학습을 진행하려고 한다. 위의 구조에서 training_set을 train / valid로 분리하여 모델의 검증하고 test 데이터로 모델 테스트를 진행한다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Flatten, Dense, GlobalAveragePooling2D
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
import math
import time
import os
import pathlib
from PIL import Image
import cv2
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns--> training set 이미지 불러오기
아레에서 train_file_path 하위에 있는 폴더에 들어가서 모든파일을 불러온뒤 이미지는 array형태로 변경 후 배열로 층층이 쌓게 된다. train_image_data 배열의 형태는 이미지 이므로 4차원으로 배열이 되며 ( sample 수 , width , height , channels) 이 된다.

label의 경우 파일이름이 dog.1.jpg , dog.2.jpg 로 되어있으므로 .을 기준으로 split 후 첫번째 값을 가져온다. 따라서 label에는 ['dog' , 'cat' ... ] (samples 수 ) 형태가 된다.
여기서 중요한 것이 total_classes와 height / width / channels 인데, 이번 실습에서는 vgg16의 feature_extraction 부분을 사용하므로 이미지를 224로 맞춰 준다. 사실 우리는 vgg16에 상위 부분은 추가로 custom 하여 사용하므로 include_top=False 옵션이 선택되어 이미지 사이즈를 변경해도 상관은 없다. 그러나 vgg16은 기본적으로 244를 사용하였으며 이미지 크기를 작게하는 것 보다 큰 편이 정보를 더 많이 담고 있으므로 예측 성능이 더 좋을 것으로 예상된다.
total_classes 의 경우에는 2진 분류이므로 2로 설정한다. channels의 수는 칼라이므로 rgb 값이 있는 3으로 하고, 흑백의 경우 1로 하면된다.


## Train 이미지 불러오기
train_file_path = './dataset/training_set/training_set'
train_image_data = []
train_image_labels = []
total_classes = 2
height = 224 ## 이미지 사이즈 중요함
width = 224 ##
channels = 3
### image 파일 주소
images_files = os.listdir(train_file_path)
for file in images_files:
path = train_file_path + "/" + file
images = os.listdir(path)
for img in images:
try:
image = cv2.imread(path + '/' + img)
image_fromarray = Image.fromarray(image,'RGB')
resize_image = image_fromarray.resize((height,width))
train_image_data.append(np.array(resize_image))
label =img.split('.')[0]
train_image_labels.append(label)
except:
print("Error - loading")
# # list --> array
train_image_data = np.array(train_image_data)
train_image_labels = np.array(train_image_labels## Test 이미지 불러오기
test_file_path = './dataset/test_set/test_set'
test_image_data = []
test_image_labels = []
total_classes = total_classes
height = height
width = width
channels = channels
### image 파일 주소
images_files = os.listdir(test_file_path)
for file in images_files:
path = test_file_path + "/" + file
images = os.listdir(path)
for img in images:
try:
image = cv2.imread(path + '/' + img)
image_fromarray = Image.fromarray(image,'RGB')
resize_image = image_fromarray.resize((height,width))
test_image_data.append(np.array(resize_image))
label =img.split('.')[0]
test_image_labels.append(label)
except:
print("Error - loading")
# # # list --> array
test_image_data = np.array(test_image_data)
test_image_labels = np.array(test_image_labels)## 데이터 확인
train_image_data.shape , train_image_labels.shape , test_image_data.shape , test_image_labels.shape
위와 같이 이미지를 불러오 뒤 배열을 확인하면 총 training 이미지 8005개와 test 이미지 2023이 잘 불러와 진 것을 확인할 수 있다.
3) 이미지 시각화
--> 이미지를 시각화 하여 고양이와 강아지 이미지를 확인해 보도록 하자. 여기서 유의 할 것이 폴더의 구조가 cats / dogs 순서로 되어 있기 때문에 배열의 앞부분에는 고양이만 있으며 , 배열의 뒷부분에는 강아지만 있다는 것이다. 이를 위해 후에 전체 데이터를 랜덤으로 섞는 과정을 추가하였다.
## 이미지 시각화
### 앞에서 10개 고양이 이미지
n = 10
plt.figure(figsize=(20, 2))
for i in range(n):
ax = plt.subplot(1, n, i + 1)
plt.title(f"{i}")
plt.imshow((train_image_data[i]))
plt.gray()
plt.show()
### 뒤에서 10개 강아지 이미지
n = 10
plt.figure(figsize=(20, 2))
for i in range(n+1):
if i > 0:
ax = plt.subplot(1, n+1, i + 1)
plt.title(f"{i}")
plt.imshow((train_image_data[-i]))
plt.gray()
plt.show()
4) 이미지 전처리 ( scaling / Augmentation)후 데이터 분리 (학습 / 검증)
--> 우선 label 배열의 경우 ['dog', 'cat' ...] 의 문자열 형태로 되어 있으므로 이 것을 숫자 형태로 변경해야 한다. 기본적으로 알고리즘에서는 숫자형태만 가능하므로 이를 encoding 해주는 것이다. 방법에는 LabelEncoding과 OneHotEncoding이 있으며 둘중 어느 것을 사용해도 상관이 없다. 사용방법에 따라 모델 학습 시 아래의 loss 를 선택적으로 사용하면 된다.

여기서는 label Encoding과 OneHotEncoding을 둘다 사용하였는 데, 이는 실습을 시간 간격을 두고 진행하면서 발생한 실수이며 ... 한가지의 방법을 사용하면 된다는 것을 기억하면 좋을 것 같다. ( 덕분에 마지막에 사진 한장으로 테스트 할때 처리할 때 inverse encoding 을 하는 방법에 대하여 알게 되었다. )
### label 값 encoding
### 앞에서 불러올 때 ['cat','dog'] 와 같이 label이 문자로 되어있으므로 숫자로 변경필요함
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train_image_labels_enc = le.fit_transform(train_image_labels)
test_image_labels_enc = le.transform(test_image_labels)### 데이터 셔플
#### Train 이미지 분리 --> train / valid
## 셔플을 통해서 이미지를 섞어서 분리
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
## 데이터 셔플
shuffle_index = np.arange(train_image_data.shape[0])
np.random.shuffle(shuffle_index)
### 셔플 시에 label encoding 된 이미지를 사용함
train_image_data = train_image_data[shuffle_index]
train_image_labels_enc = train_image_labels_enc[shuffle_index]### 데이터 분리
### 데이터 분리
## 데이터 분리
X_train , X_valid , y_train , y_valid = train_test_split(train_image_data , train_image_labels_enc , test_size=0.1, random_state=100)### y_train / y_valid One Hot Encoding ( loss에서 'sparse_croess_entropy') 사용하면 할 필요없음)
### label --> one hot encodig으로 변경
from tensorflow.keras.utils import to_categorical
## label 데이터를 one hot encoding 벡터로 변환
y_train = to_categorical(y_train , total_classes)
y_valid = to_categorical(y_valid , total_classes)X_train.shape , X_valid.shape , y_train.shape , y_valid.shape
위의 순차 과정을 통해 7024 이미지를 학습하고, 801개의 이미지를 통해 모델을 검증을 진행한다.
### ImageDataGenerator를 통해 augmentation 만든 후 data set 만들기
--> tensorflow에서 제공하는 ImageDataGenerator는 기존의 이미지를 확대 / 회전 / shift 등을 통해 학습할 수 있는 이미지를 증대(augmentation)을 수행해 준다. 또한 [ 0 , 255 ] 까지의 이미지 픽셀값을 [0 , 1]로 rescale 도 같이 진행해 준다. generator는 batch_size 만큼의 데이터 set을 반복해서 생성해 주는 역활을 수행한다.
여기서 train에만 augmentation을 수행하고 , valid나 test 데이터에는 수행하지 않는다.
### Data Augmentation (여기서 전처리 동시에 진행함) --> Train만 늘리고 valid는 늘리지 않음
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3, rotation_range=50,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2,
horizontal_flip=True, fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(X_train, y_train, batch_size=30)
val_generator = val_datagen.flow(X_valid, y_valid, batch_size=20)
4) 모델 만들기
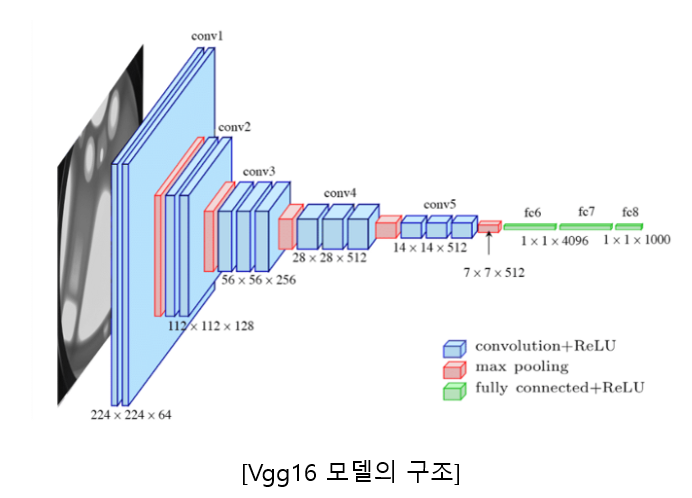
--> vgg16 의 전이학습을 사용할 시 위의 그림에서 fully connected layer만 새로 만들어서 사용하는 방법과 vgg16의 convolution 층의 일부 layer도 추가로 학습하여 미세튜닝을 하는 방법등이 존재한다. 여기서는 fully connected layer 만을 추가하여 학습에 사용하였다.
### 모델 만들기
vgg16 = VGG16(input_shape=(X_train.shape[1:]), weights='imagenet', include_top=False)
### vgg16의 모든 layer를 학습하지 않도록 함
for layer in vgg16.layers:
layer.trainable = False
add_model = keras.models.Sequential()
add_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
add_model.add(Dense(1024, activation='relu'))
add_model.add(Dense(512, activation='relu'))
add_model.add(Dense(128, activation='relu'))
add_model.add(Dense(total_classes, activation='softmax'))
model_vgg16_trans = Model(inputs=vgg16.input, outputs=add_model(vgg16.output))model_vgg16_trans.summary()
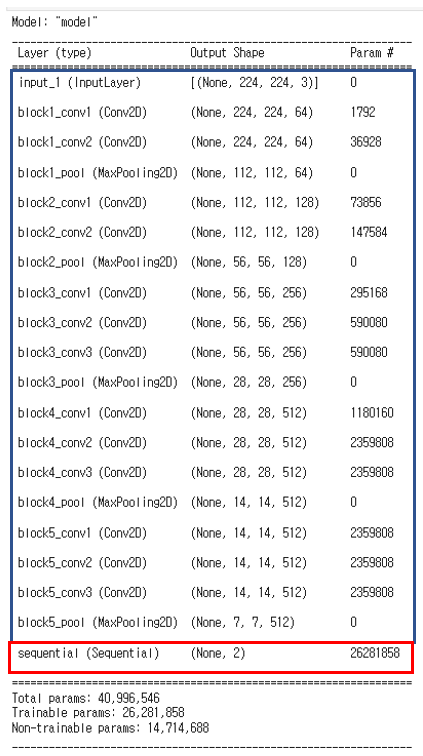
위의 모델을 확인하면 파란색 테두리는 기존의 vgg16의 convolution layer를 나타내며, 빨간색 테두리 부분은 추가로 만든
custom_layer이다. custom layer는 dense 4개의 층으로 이루어져 있는데, summay를 통해서는 sequential 내부까지 보이지 않는 것 같다.
### layer 확인
layers = [(layer, layer.name, layer.trainable) for layer in model_vgg16_trans.layers]
pd.DataFrame(layers, columns=['Layer Type', 'Layer Name', 'Layer Trainable'])layer를 확인해 보면 아래의 그림과 같이 나타나며 layer trainable의 경우 다 False로 되어있고 마지막에 실습에서 만든 sequential 부분만 학습을 진행한다는 것을 알 수 있다. 필요에 따라서는 convolution층을 선택적으로 학습에 사용하여 위에서 언급한 미세튜닝을 할 수 있다.

## complie 수행
## 위에서 ohe hot encoding 수행하지 않을 시 loss에 sparse_categorical_crossentropy 사용하면됨
model_vgg16_trans.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy'])
## early stop / model_checkpoint
early_stopping = keras.callbacks.EarlyStopping(monitor='val_loss',patience=10)
model_checkpoint = keras.callbacks.ModelCheckpoint(
filepath='./models/model_vgg16_trans/best_weights.h5',
monitor='val_loss',
save_best_only=True,
verbose=1
)
batch_size=32
history_vgg16_trans = model_vgg16_trans.fit(train_generator, steps_per_epoch=len(X_train) // batch_size, epochs=100,
validation_data=val_generator, validation_steps=len(X_valid)// batch_size, verbose=1,callbacks=[early_stopping,model_checkpoint] )
위의 코드를 확인하면 keras callback으로 early stop과 model_checkpoint를 사용하고 있다. 이는 val_loss를 확인하고 patience 의 수 만큼 변화가 없으면 종료 한다는 것이고, model_checkpoint의 경우 val_loss를 확인하면서 값이 갱신될 때마다 weight를 지정한 filepath에 저장하겠다는 것이다.
fit 메서드 내를 보면 steps_per_epoch 와 validation_steps가 있는데 이는 각각 epoch마다 몇 번의 학습을 진행할 것인지를 나타내므로 전체 데이터를 batch_size로 나누면 갯수가 나오므로 이를 사용하였으며, 1 epoch이 끝나면 몇번의 validation을 진행할 것인지가 validation_steps이다.
학습을 수행하면 아래의 파란색 박스에서 처럼 val_loss가 줄어들면 weight를 저장하고, 줄어들지 않으면 저장하지 않으며 patience 횟수가 한번 줄어들게 된다.

6) 모델 학습 및 결과 확인
### 학습 결과 확인
### 시각화 하기
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('vgg16 & Image Augmentation Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1, len(history_vgg16_trans.history['loss'])+1))
ax1.plot(epoch_list, history_vgg16_trans.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history_vgg16_trans.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, len(history_vgg16_trans.history['loss']), 1))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history_vgg16_trans.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history_vgg16_trans.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, len(history_vgg16_trans.history['loss']), 1))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
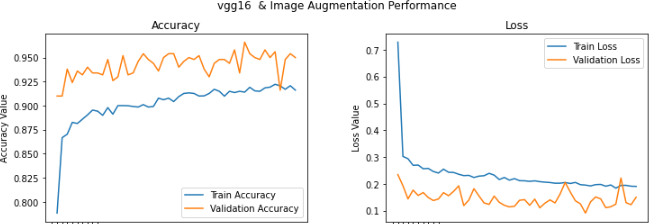
위의 학습 결과를 살펴보면 validation 의 경우 약 95% 정도의 accuracy를 보인다. 여기서 보통 Train이 validation 보다 accuracy는 높고, loss는 낮다고 생각할 수 있는데 반대의 그래프 양상을 보이는 것은 위에서 말한 것 처럼 step_per_epoch번 학습을 수행한다음에 step_per_validation을 진행하므로 학습으로 성능이 향상된 weights를 가지고 validation을 평가했기 때문에 더 높은 값을 갖는 것이다.
### Test 데이터 평가하기
### 평가하기
## label
y_test = to_categorical(test_image_labels_enc, total_classes)
## test data
test_datagen = ImageDataGenerator(
rescale=1./255,
)
test_generator = test_datagen.flow(test_image_data, y_test, batch_size=20)
## 가장 좋은 weight 불러온후 evaluate
model_vgg16_trans.load_weights('./models/model_vgg16_trans/best_weights.h5')
evaluation = model_vgg16_trans.evaluate(test_generator)
print(f"model_vgg16_trans의 loss : {evaluation[0] : .2f}")
print(f"model_vgg16_trans의 accuracy : {evaluation[1] : .2f}")
# print(model_vgg16_trans.metrics_names) ## ['loss' , 'accuracy']
Test 데이터를 평가하면 loss 0.13 과 accuracy 95%로 매우 높은 정확도를 나타내는 것을 볼 수 있다.
그럼 마지막으로 임의의 사진 한장을 가지고 평가하였을 때 어떤 결과가 나오는 지 확인해 보도록 하자
## 임의의 사진으로 모델 평가
from tensorflow.keras.preprocessing import image
np.set_printoptions(suppress=True)
import matplotlib.pyplot as plt
img_path = './dataset/dog1.jpeg'
img_a = image.load_img(img_path, target_size=(width, height))
img_array = image.img_to_array(img_a)
plt.imshow(img_array/255)
expanded_img_array = np.expand_dims(img_array, axis=0)
preprocessed_img = expanded_img_array / 255
prediction = model_vgg16_trans.predict(preprocessed_img)
prediction_arr = np.array(prediction[0])
proba = max(prediction_arr)
idx = np.argmax(prediction_arr)
pred =le.inverse_transform(np.array(idx).reshape(-1,1).ravel())
print(f"예측결과 : {pred}, 확률 : {proba * 100 : .2f}% ")

위의 사진으로 평가결과 약 80% 의 높은 확률로 dog로 에측하는 것을 확인할 수 있다.
'머신러닝 딥러닝' 카테고리의 다른 글
| [강화학습]정책기반 강화학습_Policy Gradient_Reinforce_Cartpole (0) | 2023.02.05 |
|---|---|
| [강화학습]Dqn_Mountain car_강화학습 예제 (1) | 2023.01.29 |
| [강화학습]Cartpole(카트폴) Deep Q-learning (Dqn) 실습 (0) | 2023.01.14 |
| [CNN]CAM (Class Activation Map) (1) | 2023.01.06 |
| [CNN 피처추출] 거리기반 유사 이미지 추천하기 (Flow Recognition data) (1) | 2022.12.27 |



